
Golang Map解析
参考资料
- https://www.bilibili.com/video/BV1hv411x7we/?spm_id_from=333.788.videopod.episodes&vd_source=f7d0ce024b059d57a0319d78217fa104&p=4
- https://www.linkinstars.com/post/60d021b9.html
- https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-hashmap/
- https://labuladong.online/algo/data-structure-basic/hashmap-basic/#%E5%93%88%E5%B8%8C%E5%86%B2%E7%AA%81
- https://juejin.cn/post/6977302491520040996
要点

- 最外面是hmap结构体,用buckets存放一些名字叫bmap的桶(数量不定,是2的指数倍)
- bmap是一种有8个格子的桶(一定只有8个格子),每个格子存放一对key-value
- bmap有一个overflow,用于连接下一个bmap(溢出桶)
- hmap还有oldbuckets,用于存放老数据(用于扩容时)
- mapextra用于存放非指针数据(用于优化存储和访问),内部的overflow和oldoverflow实际还是bmap的数组。
解决哈希碰撞
哈希碰撞是什么?
哈希碰撞(Hash Collision) 是指在使用哈希函数将输入映射到固定长度的哈希值时,不同的输入产生了相同的哈希值。由于哈希函数的输出空间有限,而输入空间可能非常大(甚至无限),碰撞是不可避免的。
hash(key1) = hash(key2)
上面这种情况就算是哈希碰撞了
如何解决哈希碰撞?

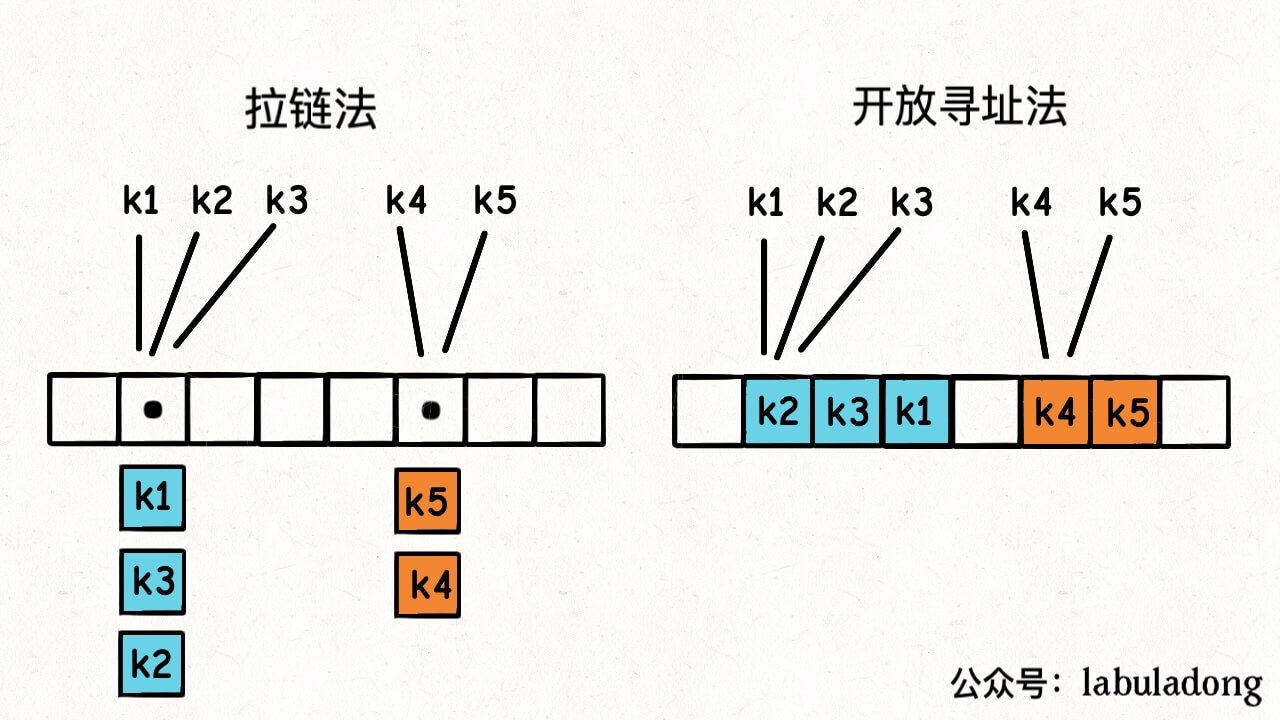
开放地址法(开放寻址法)
开放地址法写入数据
当发生碰撞的时候,将数据存储在表中的下一个位置
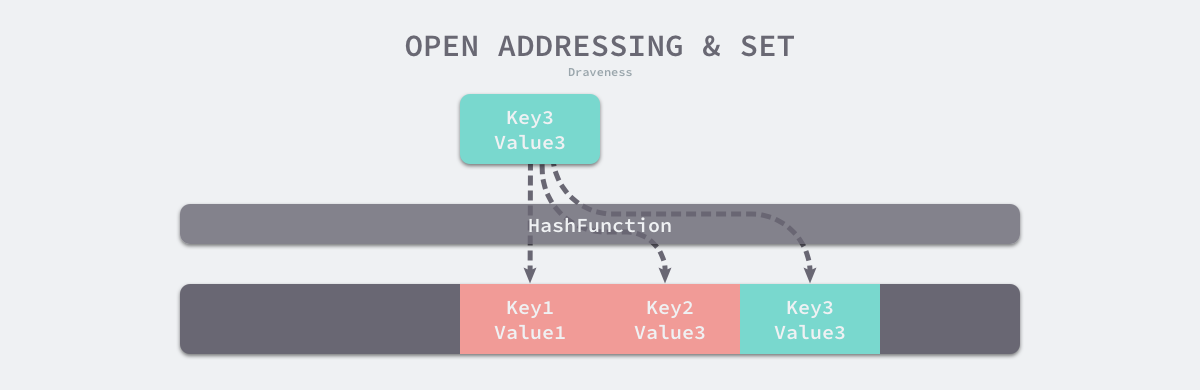
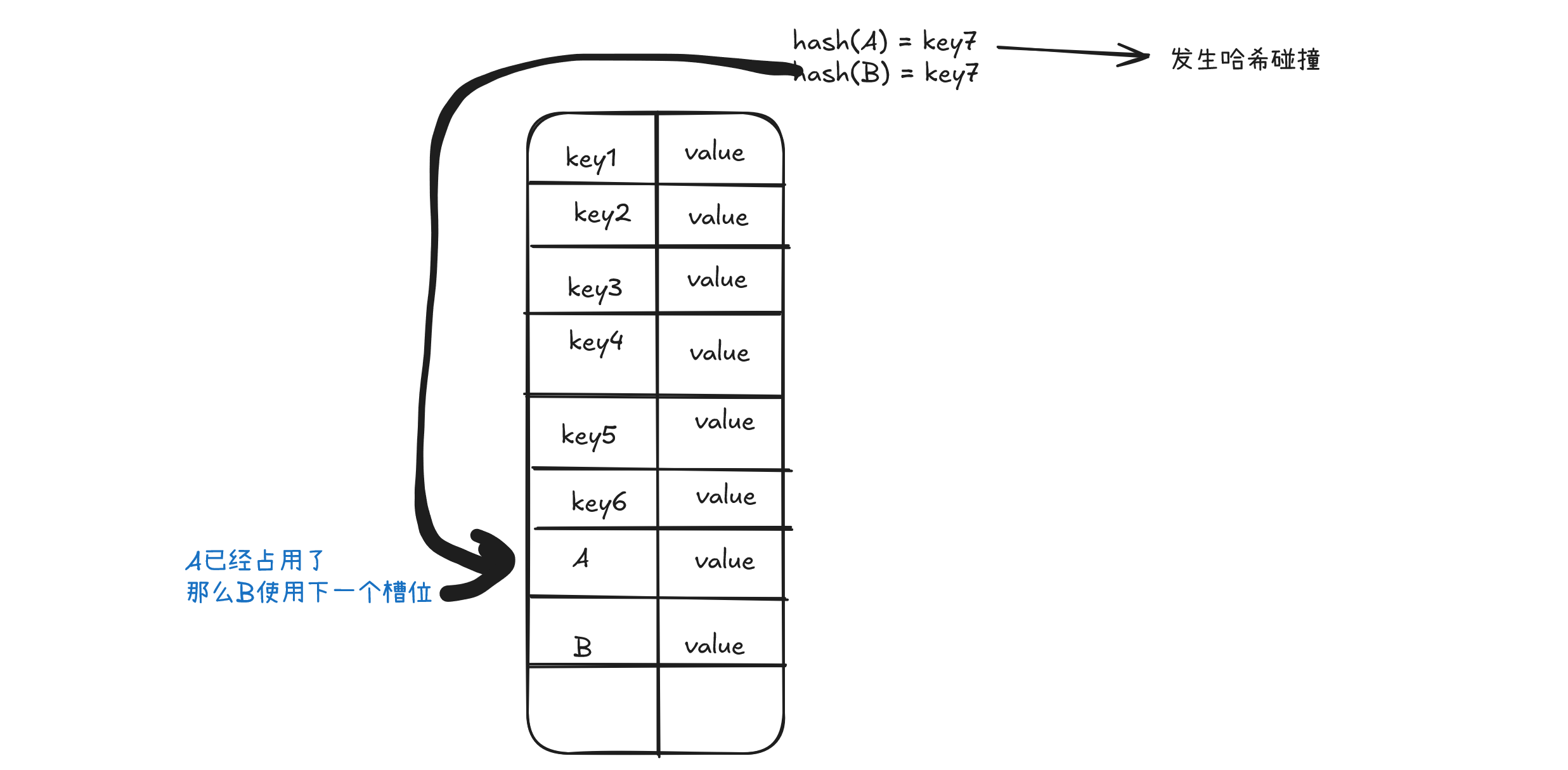
开放地址法读取数据
当需要查找某个键对应的值时,会从索引的位置开始线性探测数组,找到目标键值对或者空内存就意味着这一次查询操作的结束。
开放寻址法中对性能影响最大的是装载因子,它是数组中元素的数量与数组大小的比值。随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会影响哈希表的读写性能。当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入任意元素的时间复杂度都是 的,这时需要遍历数组中的全部元素,所以在实现哈希表时一定要关注装载因子的变化。
链地址法(拉链法)
拉链法是哈希表最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
实现拉链法一般会使用数组加上链表,不过一些编程语言会在拉链法的哈希中引入红黑树以优化性能(Java就这样),拉链法会使用链表数组作为哈希底层的数据结构,我们可以将它看成可以扩展的二维数组:
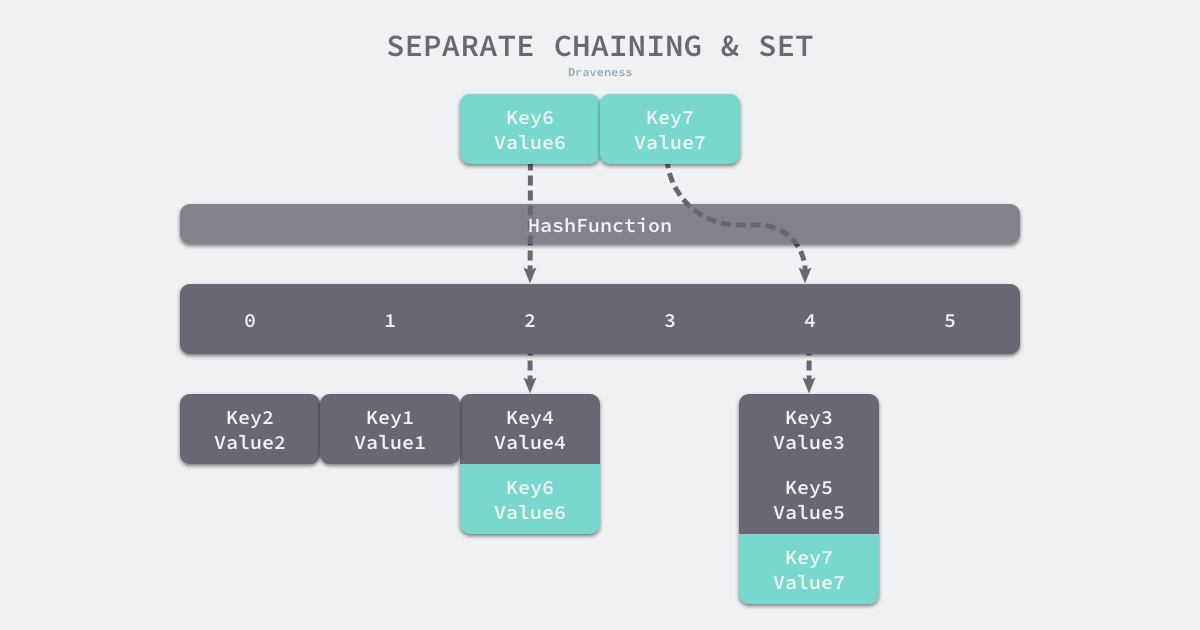
拉链法相当于是哈希表的底层数组并不直接存储 value 类型,而是存储一个链表,当有多个不同的 key 映射到了同一个索引上,这些 key -> value 对儿就存储在这个链表中,这样就能解决哈希冲突的问题。
找对应的key value的时候,先hash(key)找到索引位置,然后到索引位置发现是条链表,然后遍历这个链表找里面存的kv值,匹配到k也就是找到了
源码解析
Golang map源码
https://github.com/golang/go/blob/release-branch.go1.22/src/runtime/map.go
hmap
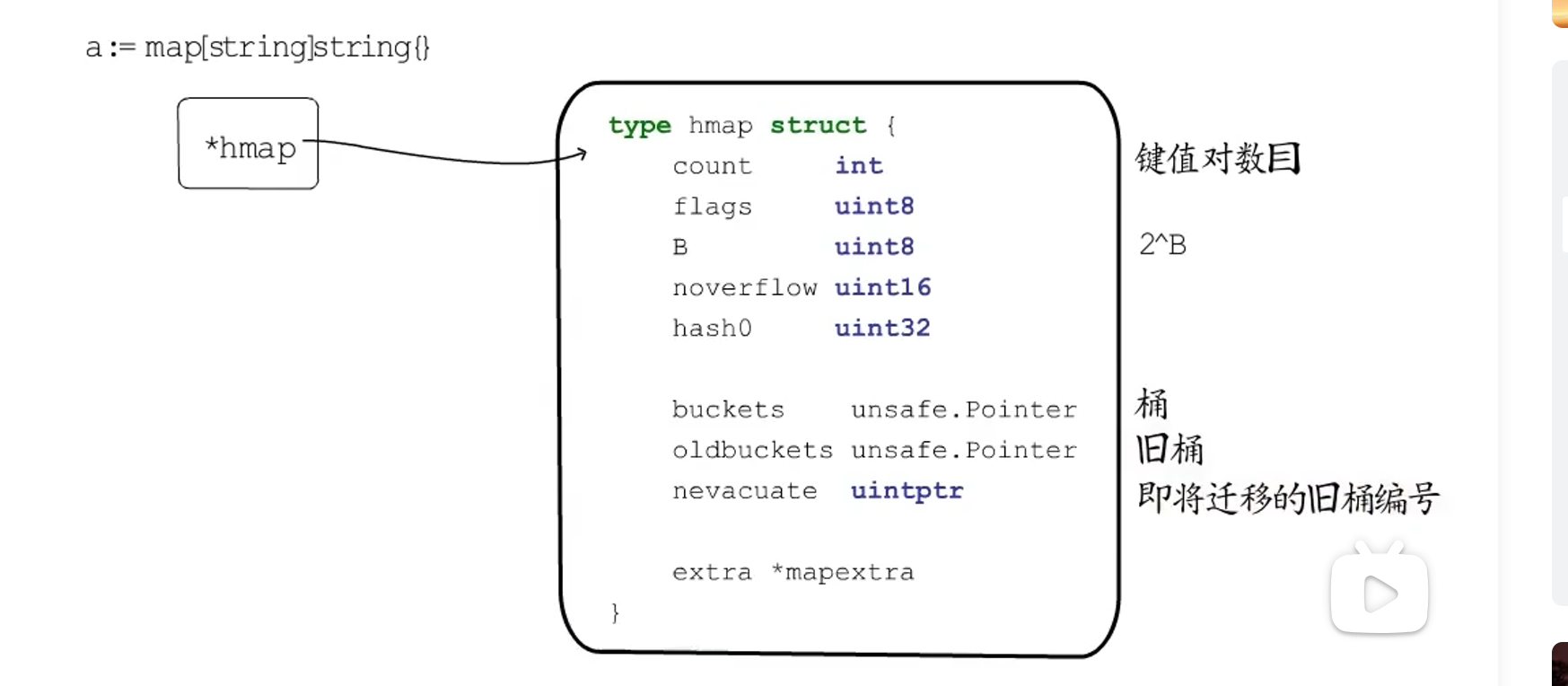
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
count是键值对数目,
flags标识当前是否为迁移状态,
B为桶的个数的Log2n(如果B为1,那就有2^1 = 2个桶)
noverflow 使用的溢出桶的数量
hash0 为对key进行hash运算得到的32位数字
buckets指向桶的地址,如果桶的个数位0(B为0)那么buckets为nil
oldbuckets 指向旧的桶的地址
nevacuate指向即将迁移的旧桶编号
extra 是一些额外的信息
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
mapextra 是 Go 语言 runtime 中与 map 实现相关的一个结构体,用于存储额外的元信息,主要用于处理 溢出桶(overflow buckets) 的情况。这些溢出桶的作用是在 map 的哈希桶(buckets)无法容纳更多键值对时,提供额外的存储空间。
以下是字段的详细解释:
overflow 和oldoverflow
-
overflow:- 是一个指针,指向一个切片,该切片保存了所有与当前哈希桶
hmap.buckets 相关的溢出桶。 - 当哈希桶中的存储空间不足时,新创建的溢出桶会被添加到这个切片中。
- 这样做可以避免直接在哈希桶结构中存储溢出信息,从而优化垃圾回收扫描过程。
- 是一个指针,指向一个切片,该切片保存了所有与当前哈希桶
-
oldoverflow:- 类似于
overflow,但用于保存与旧哈希桶hmap.oldbuckets 相关的溢出桶。 - 当 map 进行扩容时,旧桶中的数据可能会被迁移到新桶。在此期间,旧桶可能仍需要溢出桶来存储数据。
- 类似于
-
nextOverflow
-
作用:
- 指向一个空闲的溢出桶,供下次需要时使用。
-
意义:
- 在 map 中反复分配和释放溢出桶时,通过维护一个“空闲池”可以减少动态分配的次数,提高性能。
bmap(桶)
内存布局

上面的h1,h2,h3…是下面源码中的tophash,为前面hmap中hash0中的前8位
下面的k1,k2…v1,v2…是在编译时候插入到bmap结构体中的,分别是我们插入的键和值
最后的overflow是一个bmap型指针,指向一个溢出桶,它的内存布局和bmap相同,当我们一个桶被填满的时候,如果它有溢出桶,就会把新的数据存储在溢出桶上
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [abi.MapBucketCount]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
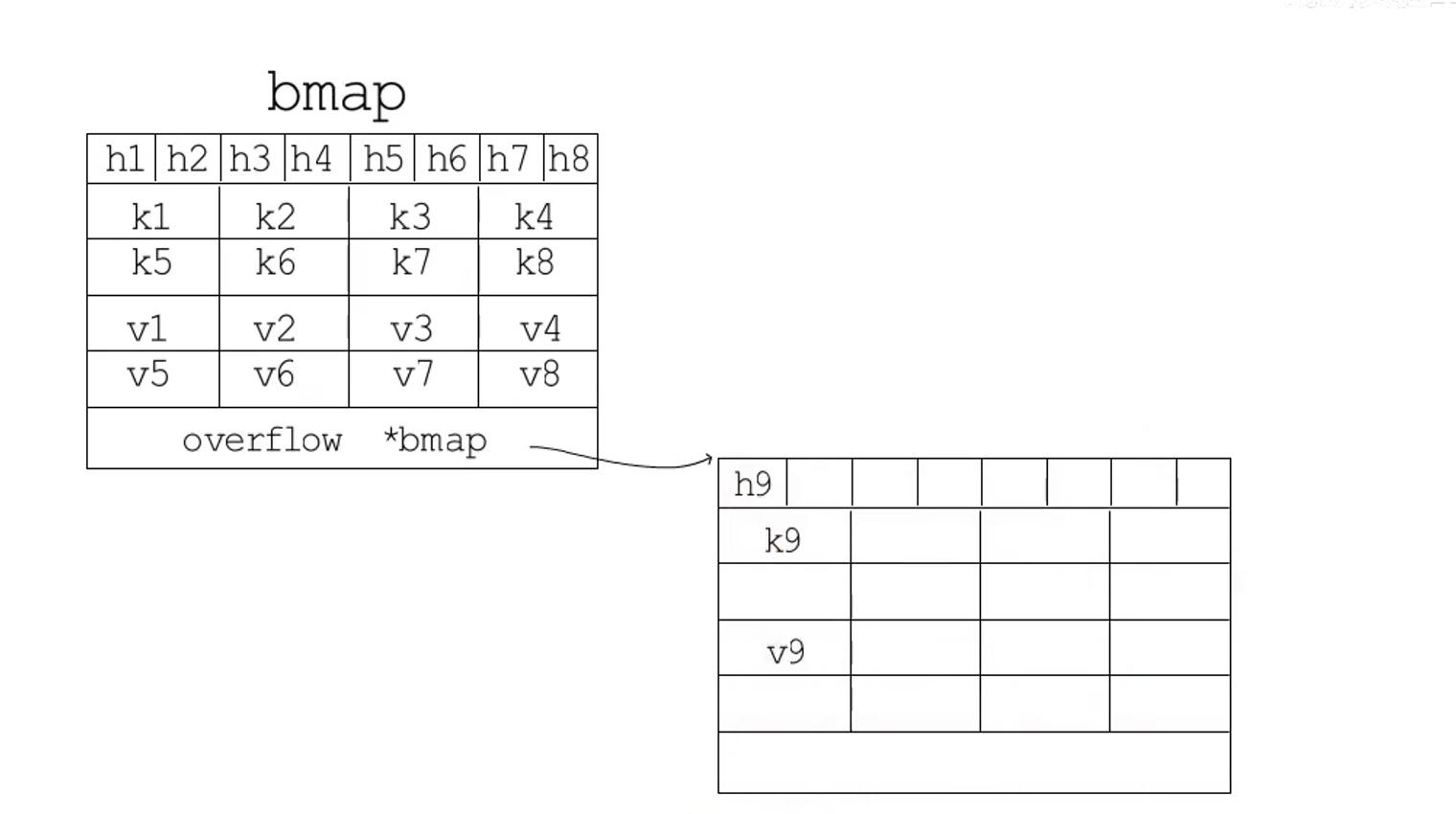
如果哈希表要分配的桶的数目大于2^4(B>4),就认为使用到溢出桶的几率比较大,就会预分配2^(B-4)个桶备用,这些溢出桶和常规桶在内存中是连续的,只是前2^B个用作常规桶,后2^B个被用作溢出桶

扩容
// 当前没有在扩容,且需要扩容
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > abi.MapBucketCount && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
// growing reports whether h is growing. The growth may be to the same size or bigger.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
装载因子
loadFactor = count / (2^B)
也就是键值对数目除以桶的个数
扩容条件
扩容条件1:负载因子(Load Factor)
负载因子的条件是,当 map 中的元素数量与桶的数量的比率超过某个阈值时,就会触发扩容。具体来说:
- Load Factor > 6.5:这意味着负载因子超出 6.5 时,
map 会进行扩容。 - 扩容后,桶的数量会翻倍(
hmap.B = hmap.B + 1)。这种扩容是为了提高哈希表的分散性,减少冲突。
负载因子控制着哈希表的负载,过高的负载因子可能会导致桶中的元素过多,从而增加冲突。
扩容条件2:溢出桶数量过多
这个条件是针对溢出桶(overflow buckets)的情况,特别是当哈希冲突集中在少数几个桶时,可能导致单个桶的溢出桶数量非常大,影响性能。
- 当 B 小于 15:如果某个桶的溢出桶数量超过
2^B,就会触发扩容。这里的B 是桶的指数,桶数量的数量级。 - 当 B >= 15:如果溢出桶的数量超过
2^15,就会触发扩容。
溢出桶的数量过多通常意味着冲突过于集中,即多个键的哈希值高位部分相同,导致它们分布在同一个桶里,进而触发了大量溢出桶。这种情况虽然负载因子可能还在合理范围内,但查询效率会受到很大影响,因为大量键值对集中在一个桶的链表中,查找时需要线性扫描链表。
进一步解释
- 为什么溢出桶过多时也会触发扩容?
溢出桶的数量过多意味着哈希函数的分布不均匀,即存在一些桶因冲突过多而堆积了过多的元素。这种情况虽然在负载因子上不一定是问题(负载因子可能还低),但性能上已经有了很大的瓶颈。特别是如果某个桶的链表非常长,查询效率会变得很低。 - 为何负载因子过高时会扩容?
当负载因子过高时,意味着桶数相对较少,冲突会频繁发生,导致哈希表的性能下降。扩容时,会增加桶的数量,并重新哈希现有的元素,从而减少冲突,提高查询性能。
总结:
你的总结是准确的,主要有两种扩容触发条件:
- 负载因子超标(
loadFactor > 6.5)会触发扩容,增加桶的数量。 - 溢出桶数量过多:如果溢出桶的数量过多,即使负载因子不高,也会触发扩容。特别是当
B < 15 时,溢出桶数量超过2^B;当B >= 15 时,超过2^15 会触发扩容。
扩容过程
哈希表扩容(rehash)的过程涉及几个关键步骤,目的是为了提高查询性能并减少冲突。以下是哈希表扩容的详细步骤:
-
判断扩容条件:
- 检查当前负载因子是否超过预设阈值(例如6.5)。
- 或者检查某个桶的溢出桶数量是否过多,超过特定限制(例如
B < 15 时超过2^B,B >= 15 时超过2^15)。
-
准备新哈希表:
- 创建一个新的哈希表,该哈希表的大小通常是当前哈希表的两倍。新的桶数量会增加,例如如果当前桶数量是
2^B,那么新桶数量将是2^(B+1)。
- 创建一个新的哈希表,该哈希表的大小通常是当前哈希表的两倍。新的桶数量会增加,例如如果当前桶数量是
-
重新哈希:
-
对现有哈希表中的每个键值对重新计算哈希值,并根据新的桶数量将它们重新分配到新的哈希表中。重新哈希的过程中,使用新的哈希函数或者新的哈希种子。
-
遍历旧哈希表中的每个桶,对每个桶中的每个键值对进行操作:
- 计算新的哈希值。
- 将键值对插入到新哈希表的相应桶中。
-
-
处理溢出桶:
- 在重新哈希的过程中,同样处理所有溢出桶中的键值对,确保它们正确地分布到新哈希表中,减少冲突。
-
更新哈希表引用:
- 完成重新哈希后,更新哈希表的内部引用,将新的哈希表设为当前使用的哈希表。
- 更新相关的内部参数,例如桶的数量、负载因子等。
渐进式扩容
渐进式扩容(incremental rehashing)是一种优化策略,用于避免哈希表在扩容过程中一次性重新哈希所有键值对,导致性能瞬间下降。它将扩容过程分解成多个小步骤,逐步完成重新哈希。以下是渐进式扩容的主要特点和步骤:
渐进式扩容的特点
- 平滑过渡:避免了传统扩容过程中一次性处理大量数据带来的性能瓶颈。
- 分步进行:将重新哈希过程分成多个小步,每次操作只处理一部分数据。
- 混合操作:在处理新的插入、查找和删除操作时,逐步完成旧数据的迁移。
渐进式扩容的步骤
-
初始化扩容:确定需要扩容时,创建一个新的哈希表,但暂时不移动任何数据。
-
设置标志:在哈希表结构中设置一个标志,表示正在进行渐进式扩容。
-
逐步迁移:
- 每次进行插入、查找或删除操作时,顺便处理旧哈希表的一小部分数据(例如一个桶)。
- 将处理过的桶中的键值对重新哈希并移动到新哈希表中。
-
更新进度:每次迁移完一部分数据后,更新标志,记录已处理的进度。
-
完成迁移:
- 当所有旧哈希表的数据都迁移到新哈希表中后,清除旧哈希表,完成扩容。
- 更新哈希表的内部引用,将新哈希表设为当前使用的哈希表。
优点
- 减少暂停时间:一次性扩容可能会导致应用程序暂停执行较长时间,而渐进式扩容将暂停时间分摊到多个操作中,显著减少影响。
- 平滑性能:避免了因一次性重新哈希大量数据而导致的性能波动,提升了用户体验。