
SnowFlake算法
什么是雪花算法
SnowFlake是Twitter开源的分布式ID生成算法
Twitter雪花算法生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。
优点
-
高性能可用: 生成时不依赖数据库,完全在内存中生成。
-
高吞吐: 每秒钟能生成数百万的自增ID
-
ID 自增: 存入数据库中,索引效率高
缺点
依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能造成ID 冲突或者重复
组成
不使用: 1bit 最高位是符号位 0 为正 1 为负,固定为0
时间戳: 41bit 毫秒级别的时间戳
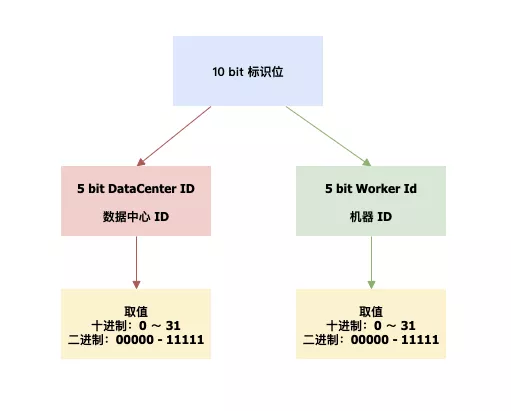
标志位: 10 bit --> 5bit 的数据中心id,5bit的工作机器ID
序列号: 12bit 递增序列号,表示节点毫秒内生成重复,通过序列号表示唯一,12bit每毫秒可以产生4096个ID
通过序列号1毫秒能生成4096个不重复id,一秒能生成 1000 * 4096个不重复id
默认的雪花算法是64bit,具体的长度可以自行配置,如果希望运行更久,增加时间戳的位数;
如果需要支持更多节点部署,增加标志位长度
如果并发很高,增加序列号位数
应用场景
- 分布式系统唯一ID生成:在分布式系统中,由于多个节点可能同时生成ID,很容易出现ID冲突的问题。雪花算法通过分配不同的工作机器ID,可以保证在不同的节点上生成的ID是唯一的。
- 大数据存储和处理:在大数据领域,经常需要为大量的数据记录生成唯一标识。雪花算法可以生成高效、有序且唯一的ID,便于数据的存储和管理。
- 社交媒体平台:在社交媒体平台上,用户生成内容的ID、用户ID等都需要是唯一的。雪花算法可以帮助平台高效地生成这些ID。
- 电商网站订单号生成:在电商网站上,每笔订单都需要一个唯一的订单号。雪花算法可以快速、有序地生成订单号,便于订单的管理和处理。
- 日志记录与分析:在系统日志记录中,每一项日志都需要一个唯一的标识。雪花算法生成的有序ID,有助于日志的排序和分析。
- 分布式数据库:在分布式数据库中,为每个数据记录生成唯一ID是一个常见的需求。雪花算法可以为数据库中的记录生成高效、有序的唯一ID。