Golang设计模式
Golang设计模式
一.面向对象设计原则

1.1 单一职责原则
类的职责单一,对外只提供一种功能,而引起类变化的原因都应该只有一个。
//不遵守单一职责原则
package main
import "fmt"
/*
在这个例子中,Clothes 类包含了两个方法 onWork() 和 onShop(),这两个方法描述了在不同场景下(工作和购物)穿着相同的装扮。
问题在于这两种场景虽然使用了相同的装扮,
但它们实际上是两种不同的行为或上下文。
*/
type Clothes struct{}
func (c *Clothes) onWork() {
fmt.Println("工作的装扮")
}
func (c *Clothes) onShop() {
fmt.Println("购物的装扮")
}
func main() {
c := Clothes{}
//逛街的业务
c.onShop()
//工作的业务
c.onWork()
}
//这个修改后的代码确实更好地遵守了单一职责原则。现在有两个不同的类,WorkClothes 和 ShopClothes,它们分别负责工作和购物时的装扮。每个类都有一个明确的职责,即定义了在某个特定场合下的装扮。
package main
import "fmt"
type ShopClothes struct {
}
type WorkClothes struct{}
func (c *WorkClothes) onWork() {
fmt.Println("工作的装扮")
}
func (c *ShopClothes) onShop() {
fmt.Println("购物的装扮")
}
func main() {
c := &WorkClothes{}
c.onWork()
c1 := &ShopClothes{}
c1.onShop()
}
在面向对象编程的过程中,设计一个类,建议对外提供的功能单一,接口单一,影响一个类的范围就只限定在这一个接口上,一个类的一个接口具备这个类的功能含义,职责单一不复杂。
1.2 开闭原则
开闭原则(Open-Closed Principle, OCP)是面向对象设计中的一个重要原则,它指出软件实体(如类、模块、函数等)应该是对扩展开放的,对修改关闭的。这意味着我们可以扩展一个类的行为而不修改它的源代码。
//不满足开闭原则
package main
import "fmt"
// 假设我们有一个系统用于处理不同类型的订单,例如普通订单和紧急订单。最初系统只支持普通订单,后来需要增加对紧急订单的支持。
type Order struct {
}
func (o *Order) Process() {
fmt.Println("处理普通订单")
}
func main() {
o := &Order{}
o.Process()
}
---
package main
import "fmt"
type Order struct{}
func (o *Order) Process(){
fmt.Println("处理普通订单")
}
func (o *Order) ProcessUrgently() {
fmt.Println("处理紧急订单")
}
func main(){
o := &Order{}
o.Process()
o.ProcessUrgently()
}
这个修改违反了开闭原则,因为我们直接修改了原有的 Order 类来添加新的功能。如果以后需要添加更多类型的订单处理逻辑(如VIP订单处理),我们可能还需要继续修改 Order 类,这会导致代码难以维护。
package main
import "fmt"
type OrderHandler interface {
Handle()
}
type NormalOrder struct{}
func (n *NormalOrder) Handle() {
fmt.Println("处理普通订单")
}
type UrgentOrder struct{}
func (u *UrgentOrder) Handle() {
fmt.Println("紧急处理订单")
}
func main() {
normalOrder := &NormalOrder{}
normalOrder.Handle()
urgentOrder := &UrgentOrder{}
urgentOrder.Handle()
}
-
定义接口:
- 我们定义了一个
OrderHandler 接口,其中包含一个Handle 方法。
- 我们定义了一个
-
实现接口:
NormalOrder 结构体实现了OrderHandler 接口,并定义了Handle 方法来处理普通订单。UrgentOrder 结构体同样实现了OrderHandler 接口,并定义了Handle 方法来处理紧急订单。
-
扩展性:
- 如果需要添加新的订单类型(如 VIP 订单),我们只需创建一个新的结构体来实现
OrderHandler 接口,并提供相应的Handle 方法实现即可。 - 这意味着我们可以扩展系统,而不需要修改现有代码。
- 如果需要添加新的订单类型(如 VIP 订单),我们只需创建一个新的结构体来实现
1.3 依赖倒置原则
依赖倒置原则(Dependency Inversion Principle, DIP)是一种面向对象设计的原则,它提倡高层模块不应该依赖于低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。
依赖倒置原则鼓励我们使用接口或抽象基类来定义模块之间的交互,而不是直接依赖于具体的实现。这样可以降低系统的耦合度,提高模块的复用性和灵活性。
示例:发送通知系统
假设我们有一个应用需要发送通知给用户,这些通知可以是电子邮件、短信或推送通知。我们将使用依赖倒置原则来设计这个系统。
-
定义接口:
- 我们定义了一个
Notifier 接口,它包含一个SendNotification 方法,用于发送通知。
- 我们定义了一个
-
实现接口:
EmailNotifier 结构体实现了Notifier 接口,并定义了SendNotification 方法来发送电子邮件通知。SmsNotifier 结构体实现了Notifier 接口,并定义了SendNotification 方法来发送短信通知。PushNotifier 结构体实现了Notifier 接口,并定义了SendNotification 方法来发送推送通知。
-
使用依赖注入:
NotificationService 结构体通过构造函数接收一个Notifier 接口类型的参数,这样可以根据需要传入不同的通知实现。
-
扩展性:
- 如果需要添加新的通知方式(如电话通知),我们只需创建一个新的结构体来实现
Notifier 接口,并提供相应的SendNotification 方法实现即可。 - 这意味着我们可以扩展系统,而不需要修改现有代码。
- 如果需要添加新的通知方式(如电话通知),我们只需创建一个新的结构体来实现
通过这种方式,我们遵循了依赖倒置原则:
- 高层模块依赖于抽象:
NotificationService 依赖于Notifier 接口,而不是具体的实现。 - 抽象不依赖于细节:
Notifier 接口定义了通知的基本行为,而具体的实现(如EmailNotifier,SmsNotifier,PushNotifier)依赖于这个接口。 - 低层模块依赖于抽象:每个具体的实现都实现了
Notifier 接口,从而依赖于抽象。
package main
import "fmt"
type Notifier interface {
SendNotification(string)
}
type SmsNotifier struct {
}
type EmailNotifier struct {
}
type WechatNotifier struct{}
// 定义一个通知服务,使用依赖注入的方式接收通知器
type NotificationService struct {
notifier Notifier
}
func (sms *SmsNotifier) SendNotification(msg string) {
fmt.Println("send sms", msg)
}
func (email *EmailNotifier) SendNotification(msg string) {
fmt.Println("send email", msg)
}
func (wechat *WechatNotifier) SendNotification(msg string) {
fmt.Println("send wechat", msg)
}
func NewNotificationService(notifier *Notifier) *NotificationService {
return &NotificationService{
notifier: *notifier,
}
}
func (ns *NotificationService) Notify() {
ns.notifier.SendNotification("meowrain")
}
func main() {
sms := &SmsNotifier{}
email := &EmailNotifier{}
wechat := &WechatNotifier{}
ns1 := NewNotificationService(&sms)
ns2 := NewNotificationService(&email)
ns3 := NewNotificationService(&wechat)
ns1.Notify()
ns2.Notify()
ns3.Notify()
}
1.4 合成复用原则
合成复用原则(Composite Reuse Principle, CRP)提倡使用对象组合而非继承来实现复用。也就是说,我们应该优先考虑通过对象的组合来重用现有代码,而不是通过继承来重用代码。这样可以减少继承体系的复杂性,并提高系统的灵活性。
假设我们有一个系统需要处理各种类型的文档,例如 PDF 文档和 Word 文档。我们可以使用组合的方式来实现这些文档的处理。
package main
import "fmt"
// 定义一个通用的文档处理器接口
type DocumentProcessor interface {
Process()
}
// 实现 PDF 文档处理器
type PdfDocumentProcessor struct{}
func (p *PdfDocumentProcessor) Process() {
fmt.Println("处理 PDF 文档")
}
// 实现 Word 文档处理器
type WordDocumentProcessor struct{}
func (w *WordDocumentProcessor) Process() {
fmt.Println("处理 Word 文档")
}
// 定义一个文档处理器服务,使用组合的方式包含具体的处理器
type DocumentService struct {
processor DocumentProcessor
}
func NewDocumentService(processor DocumentProcessor) *DocumentService {
return &DocumentService{processor: processor}
}
func (ds *DocumentService) ProcessDocument() {
ds.processor.Process()
}
func main() {
pdfProcessor := &PdfDocumentProcessor{}
wordProcessor := &WordDocumentProcessor{}
pdfService := NewDocumentService(pdfProcessor)
wordService := NewDocumentService(wordProcessor)
pdfService.ProcessDocument()
wordService.ProcessDocument()
}
解释
-
定义接口:
- 我们定义了一个
DocumentProcessor 接口,它包含一个Process 方法,用于处理文档。
- 我们定义了一个
-
实现接口:
PdfDocumentProcessor 结构体实现了DocumentProcessor 接口,并定义了Process 方法来处理 PDF 文档。WordDocumentProcessor 结构体实现了DocumentProcessor 接口,并定义了Process 方法来处理 Word 文档。
-
使用组合:
DocumentService 结构体通过构造函数接收一个DocumentProcessor 接口类型的参数,这样可以根据需要传入不同的文档处理器实现。
-
扩展性:
- 如果需要添加新的文档类型(如 TXT 文档),我们只需创建一个新的结构体来实现
DocumentProcessor 接口,并提供相应的Process 方法实现即可。 - 这意味着我们可以扩展系统,而不需要修改现有代码。
- 如果需要添加新的文档类型(如 TXT 文档),我们只需创建一个新的结构体来实现
通过这种方式,我们遵循了合成复用原则:
- 使用组合而非继承:
DocumentService 通过组合DocumentProcessor 实现来处理不同的文档类型,而不是通过继承来复用代码。 - 提高了灵活性:如果需要添加新的文档类型,只需添加新的处理器实现即可,而无需修改现有代码
1.5 迪米特法则
一个对象应当对其他对象尽可能少的了解,从而降低各个对象之间的耦合,提高系统的可维护性。例如在一个程序中,各个模块之间相互调用时,通常会提供一个统一的接口来实现。这样其他模块不需要了解另外一个模块的内部实现细节,这样当一个模块内部的实现发生改变时,不会影响其他模块的使用。(黑盒原理)
示例:聊天室系统
假设我们有一个简单的聊天室系统,用户可以发送消息给其他人。我们可以使用中介者模式来避免用户对象直接相互引用,从而降低耦合度。
如果这个聊天室系统的代码没有遵循迪米特法则,那么用户对象可能会直接相互引用,导致对象之间的耦合度增加。下面是一个未遵循迪米特法则的版本,用户对象直接向其他用户发送消息:
package main
import "fmt"
// 定义用户
type User struct {
name string
friends []User
}
func (u *User) AddFriend(friend User) {
u.friends = append(u.friends, friend)
}
func (u *User) Send(message string) {
fmt.Printf("%s: 发送消息 '%s'\n", u.name, message)
for _, friend := range u.friends {
friend.Receive(message)
}
}
func (u *User) Receive(message string) {
fmt.Printf("%s: 收到消息 '%s'\n", u.name, message)
}
func NewUser(name string) *User {
return &User{name: name, friends: make([]User, 0)}
}
func main() {
alice := NewUser("Alice")
bob := NewUser("Bob")
charlie := NewUser("Charlie")
alice.AddFriend(*bob)
alice.AddFriend(*charlie)
bob.AddFriend(*alice)
bob.AddFriend(*charlie)
charlie.AddFriend(*alice)
charlie.AddFriend(*bob)
alice.Send("你好,大家!")
bob.Send("嗨,Alice!")
charlie.Send("很高兴见到你们!")
}
使用中介者模式可以解决这个问题
package main
import "fmt"
// 定义中介者接口
type Mediator interface {
SendMessage(message string, user User)
}
// 定义用户接口
type User interface {
Send(message string)
Receive(message string)
}
// 实现中介者
type ChatRoom struct{}
func (cr *ChatRoom) SendMessage(message string, user User) {
fmt.Printf("消息 '%s' 发送给所有用户\n", message)
for _, u := range users {
if u != user {
u.Receive(message)
}
}
}
var users = make([]User, 0)
func (cr *ChatRoom) AddUser(user User) {
users = append(users, user)
}
// 实现用户
type UserImpl struct {
name string
}
func (u *UserImpl) Send(message string) {
fmt.Printf("%s: 发送消息 '%s'\n", u.name, message)
chatRoom.SendMessage(message, u)
}
func (u *UserImpl) Receive(message string) {
fmt.Printf("%s: 收到消息 '%s'\n", u.name, message)
}
func NewUser(name string) *UserImpl {
return &UserImpl{name: name}
}
func main() {
chatRoom := &ChatRoom{}
alice := NewUser("Alice")
bob := NewUser("Bob")
charlie := NewUser("Charlie")
chatRoom.AddUser(alice)
chatRoom.AddUser(bob)
chatRoom.AddUser(charlie)
alice.Send("你好,大家!")
bob.Send("嗨,Alice!")
charlie.Send("很高兴见到你们!")
}
解释
-
定义接口:
- 我们定义了一个
Mediator 接口,它包含一个SendMessage 方法,用于转发消息。 - 我们还定义了一个
User 接口,它包含一个Send 方法用于发送消息和一个Receive 方法用于接收消息。
- 我们定义了一个
-
实现接口:
ChatRoom 结构体实现了Mediator 接口,并定义了SendMessage 方法来转发消息。UserImpl 结构体实现了User 接口,并定义了Send 和Receive 方法来发送和接收消息。
-
使用中介者模式:
- 用户通过
ChatRoom 对象发送消息,而不是直接相互引用。 ChatRoom 负责管理用户列表并将消息转发给其他用户。
- 用户通过
-
扩展性:
- 如果需要添加新的用户,只需创建新的
UserImpl 实例并通过ChatRoom 对象进行注册即可。
- 如果需要添加新的用户,只需创建新的
通过这种方式,我们遵循了迪米特法则:
- 对象之间的交互保持在最小范围内:用户对象通过
ChatRoom 中介者进行通信,而不是直接相互引用。 - 降低了系统的耦合度:如果需要添加新的用户或改变消息传递的逻辑,只需修改
ChatRoom 的实现,而无需修改用户对象的代码。
二.设计模式
2.1 创建型模式
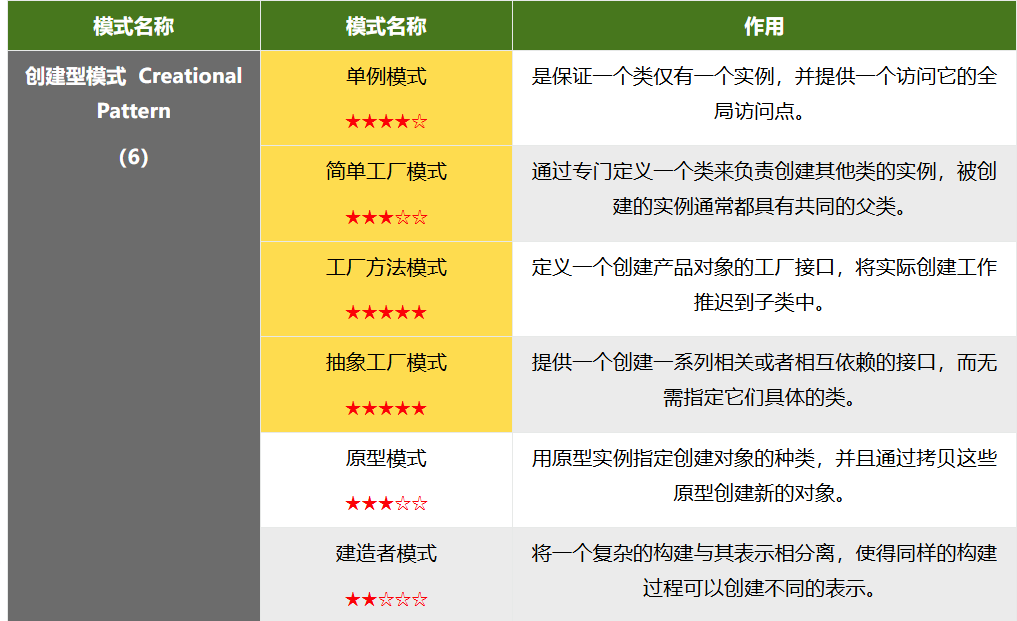
2.1.1 单例模式
是保证一个类仅有一个实例,并提供一个访问它的全局访问点。
单例模式要解决的问题是:
保证一个类永远只能有一个对象,且该对象的功能依然能被其他模块使用。

package singleton
import "fmt"
type instance struct {
name string
}
var ins *instance = new(instance)
func (ins *instance) Work() {
fmt.Println("work")
}
func GetInstance(name string) *instance {
ins.name = name
return ins
}
package singletontest
import "singleton"
func hello() {
s := singleton.GetInstance()
s.Work()
}
上面代码中,我们提前实例化了instance,然后创建了一个GetInstance方法来获取这个对象
在另外一个包里,我们只能通过GetInstance获取这个示例对象并调用它的函数
上面代码推演了一个单例的创建和逻辑过程,上述是单例模式中的一种,属于“饿汉式”。含义是,在初始化单例唯一指针的时候,就已经提前开辟好了一个对象,申请了内存。饿汉式的好处是,不会出现线程并发创建,导致多个单例的出现,但是缺点是如果这个单例对象在业务逻辑没有被使用,也会客观的创建一块内存对象。那么与之对应的模式叫“懒汉式”,代码如下:
package singleton
import "fmt"
type instance struct {
name string
}
var ins *instance
func (ins *instance) Work() {
fmt.Println("work")
}
func GetInstance(name string) *instance {
if ins == nil {
ins = new(instance)
ins.name = name
return ins
}
ins.name = name
return ins
}
线程安全的单例模式实现
上面的“懒汉式”实现是非线程安全的设计方式,也就是如果多个线程或者协程同时首次调用GetInstance()方法有概率导致多个实例被创建,则违背了单例的设计初衷。那么在上面的基础上进行修改,可以利用Sync.Mutex进行加锁,保证线程安全。这种线程安全的写法,有个最大的缺点就是每次调用该方法时都需要进行锁操作,在性能上相对不高效,具体的实现改进如下:
package singleton
import (
"fmt"
"sync"
)
type instance struct {
name string
}
var lock sync.Mutex
var ins *instance
func (ins *instance) Work() {
fmt.Println("work")
}
func GetInstance(name string) *instance {
lock.Lock()
defer lock.Unlock()
if ins == nil {
ins = new(instance)
ins.name = name
return ins
}
ins.name = name
return ins
}
上面代码虽然解决了线程安全,但是每次调用GetInstance()都要加锁会极大影响性能。所以接下来可以借助"sync/atomic"来进行内存的状态存留来做互斥。atomic就可以自动加载和设置标记,代码如下:
package singleton
import (
"fmt"
"sync"
"sync/atomic"
)
type instance struct {
name string
}
var initialized uint32
var lock sync.Mutex
var ins *instance
func (ins *instance) Work() {
fmt.Println("work")
}
func GetInstance(name string) *instance {
//如果标记为被设置,直接返回,不加锁
if atomic.LoadUint32(&initialized) == 1 {
ins.name = name
return ins
}
//如果没有,则加锁申请
lock.Lock()
defer lock.Unlock()
if initialized == 0 {
ins = new(instance)
ins.name = name
//设置标记位
atomic.StoreUint32(&initialized, 1)
}
return ins
}
述的实现其实Golang有个方法已经帮助开发者实现完成,就是Once模块,来看下Once.Do()方法的源代码
func (o *Once) Do(f func()) { //判断是否执行过该方法,如果执行过则不执行
if atomic.LoadUint32(&o.done) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
package singleton
import (
"fmt"
"sync"
)
type instance struct {
name string
}
var once sync.Once
var ins *instance
func (ins *instance) Work() {
fmt.Println("work")
}
func GetInstance(name string) *instance {
once.Do(func() {
ins = new(instance)
ins.name = name
})
return ins
}
优缺点
优点:
(1) 单例模式提供了对唯一实例的受控访问。
(2) 节约系统资源。由于在系统内存中只存在一个对象。
缺点:
(1) 扩展略难。单例模式中没有抽象层。
(2) 单例类的职责过重。
适用场景
(1) 系统只需要一个实例对象,如系统要求提供一个唯一的序列号生成器或资源管理器,或者需要考虑资源消耗太大而只允许创建一个对象。
(2) 客户调用类的单个实例只允许使用一个公共访问点,除了该公共访问点,不能通过其他途径访问该实例。
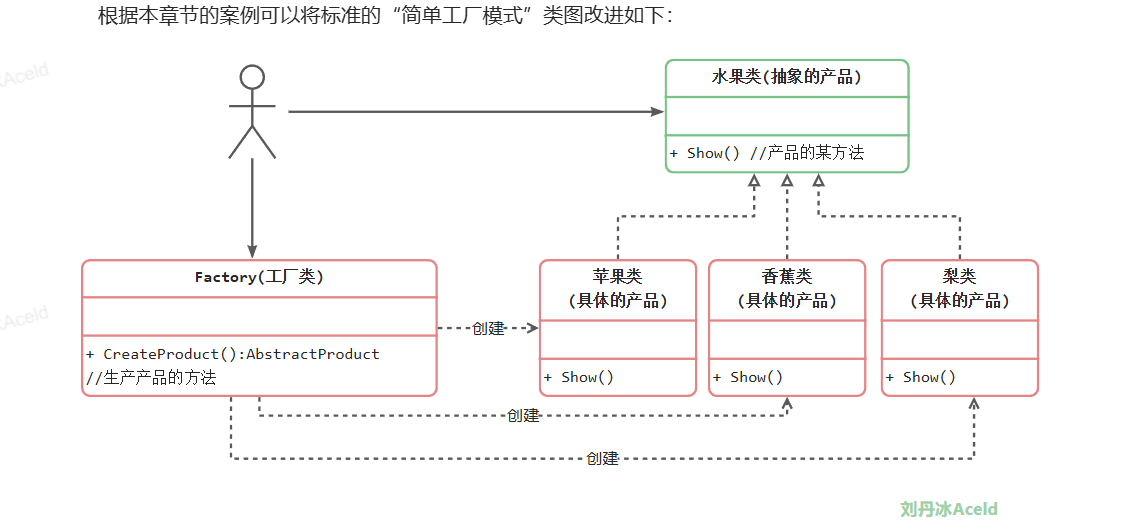
2.1.2 简单工厂模式
package simplefactory
import "fmt"
type Fruit struct {
}
func (f *Fruit) Show(name string) {
if name == "apple" {
fmt.Println("我是苹果")
} else if name == "banana" {
fmt.Println("我是香蕉")
} else if name == "pear" {
fmt.Println("我是梨")
}
}
func NewFruit(name string) *Fruit {
fruit := new(Fruit)
if name == "apple" {
//创建apple逻辑
} else if name == "banana" {
//创建banana逻辑
} else if name == "pear" {
//创建pear逻辑
}
return fruit
}
func main() {
apple := NewFruit("apple")
apple.Show("apple")
banana := NewFruit("banana")
banana.Show("banana")
pear := NewFruit("pear")
pear.Show("pear")
}
不难看出,Fruit类是一个“巨大的”类,在该类的设计中存在如下几个问题:
(1) 在Fruit类中包含很多“if…else…”代码块,整个类的代码相当冗长,代码越长,阅读难度、维护难度和测试难度也越大;而且大量条件语句的存在还将影响系统的性能,程序在执行过程中需要做大量的条件判断。
(2) Fruit类的职责过重,它负责初始化和显示所有的水果对象,将各种水果对象的初始化代码和显示代码集中在一个类中实现,违反了“单一职责原则”,不利于类的重用和维护;
(3) 当需要增加新类型的水果时,必须修改Fruit类的构造函数NewFruit()和其他相关方法源代码,违反了“开闭原则”。

简单工厂模式并不属于GoF的23种设计模式。他是开发者自发认为的一种非常简易的设计模式,其角色和职责如下:
**工厂(Factory)角色**:简单工厂模式的核心,它负责实现创建所有实例的内部逻辑。工厂类可以被外界直接调用,创建所需的产品对象。
**抽象产品(AbstractProduct)角色**:简单工厂模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
**具体产品(Concrete Product)角色**:简单工厂模式所创建的具体实例对象。
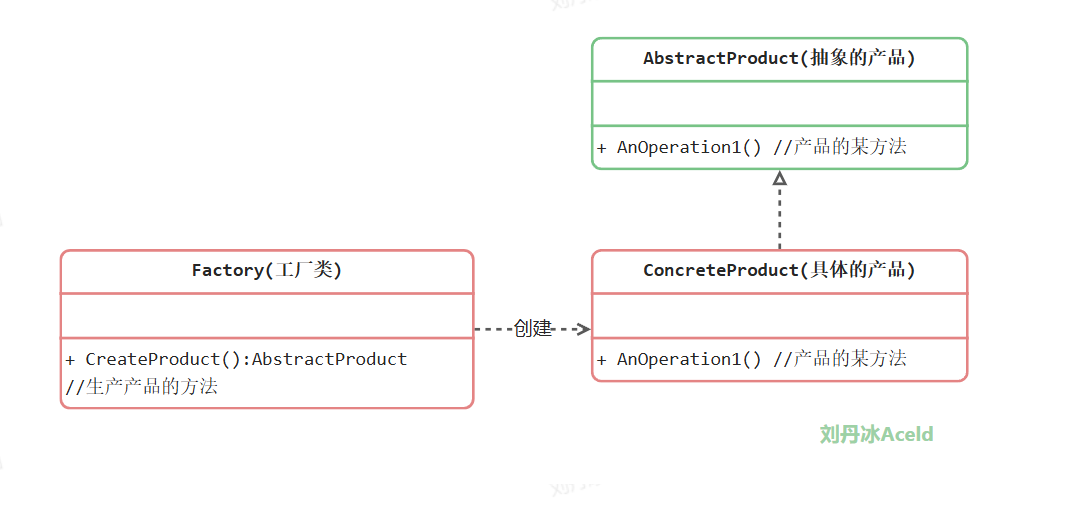
实现:
package simplefactory
type Factory struct{}
func (f *Factory) CreateFruit(name string) Fruit {
switch name {
case "apple":
return &Apple{}
case "banana":
return &Banana{}
default:
return nil
}
}
type Fruit interface {
Show()
}
type Apple struct{}
type Banana struct{}
func (a *Apple) Show() {
println("this is apple")
}
func (b *Banana) Show() {
println("this is banana")
}
func main() {
var fac Factory = Factory{}
apple := fac.CreateFruit("apple")
apple.Show()
banana := fac.CreateFruit("banana")
banana.Show()
}
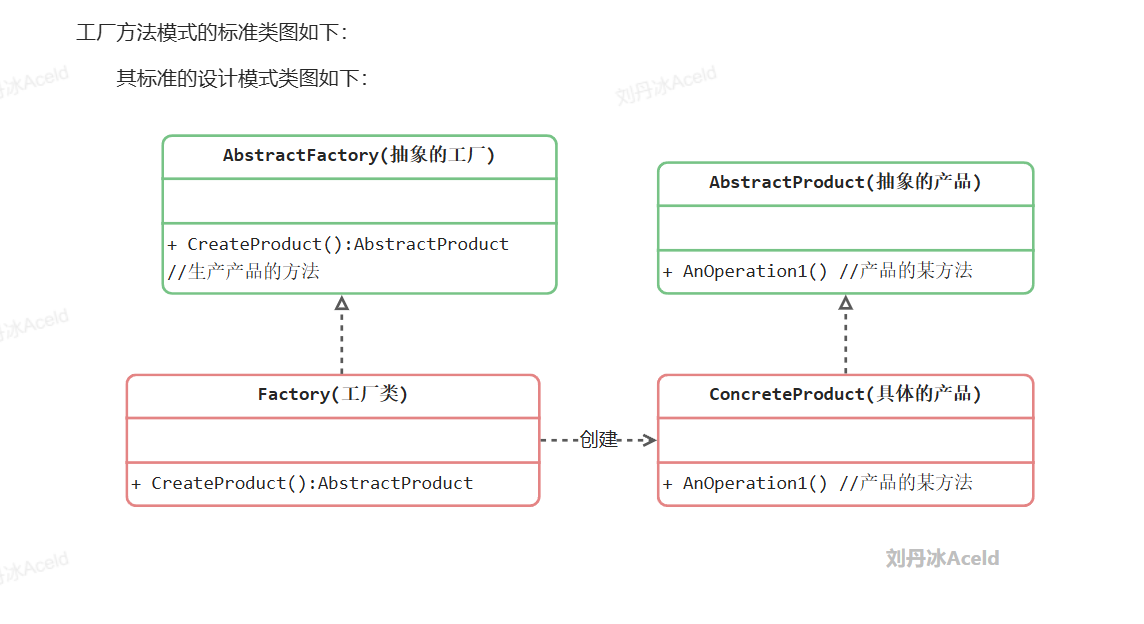
2.1.3 工厂方法模式
抽象工厂(Abstract Factory)角色:工厂方法模式的核心,任何工厂类都必须实现这个接口。
工厂(Concrete Factory)角色:具体工厂类是抽象工厂的一个实现,负责实例化产品对象。
抽象产品(Abstract Product)角色:工厂方法模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
具体产品(Concrete Product)角色:工厂方法模式所创建的具体实例对象。
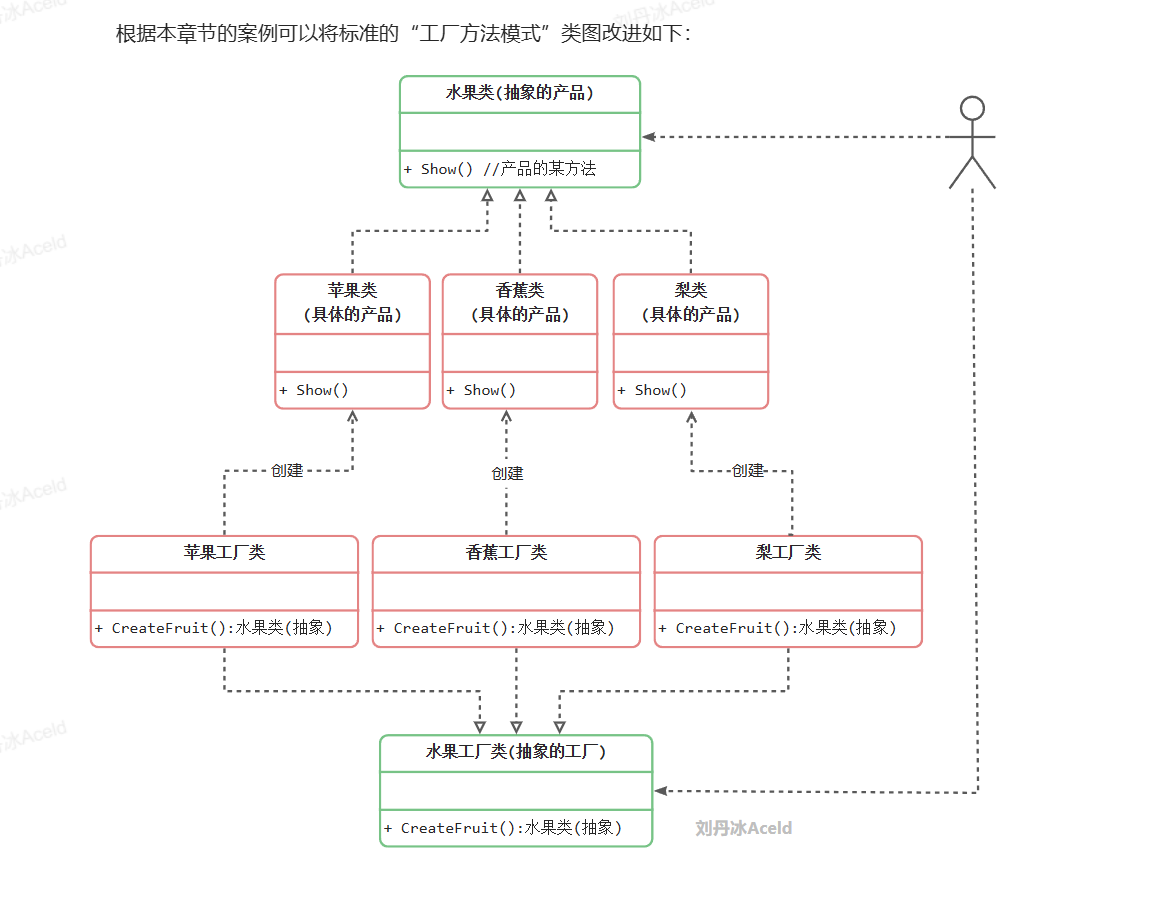
实现:
package factory
type Fruit interface {
Show()
}
type Apple struct {
}
type Banana struct{}
type Pear struct{}
func (a *Apple) Show() {
println("我是苹果")
}
func (b *Banana) Show() {
println("我是香蕉")
}
func (p *Pear) Show() {
println("我是梨")
}
type FruitFactory interface {
CreateFruit() Fruit
}
type AppleFactory struct {
}
type PearFactory struct {
}
type BananaFactory struct {
}
func (applefac *AppleFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &Apple{}
return fruit
}
func (pearfac *PearFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &Pear{}
return fruit
}
func (bananafac *BananaFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &Banana{}
return fruit
}
func main() {
var applefactory FruitFactory
applefactory = new(AppleFactory)
apple := applefactory.CreateFruit()
apple.Show()
var pearfactory FruitFactory
pearfactory = new(PearFactory)
pear := pearfactory.CreateFruit()
pear.Show()
var bananafactory FruitFactory
bananafactory = new(BananaFactory)
banana := bananafactory.CreateFruit()
banana.Show()
}
上述代码是通过面向抽象层开发,业务逻辑层的main()函数逻辑,依然是只与工厂耦合,且只与抽象的工厂和抽象的水果类耦合,这样就遵循了面向抽象层接口编程的原则。
那么抽象的工厂方法模式如何体现“开闭原则”的。接下来可以尝试在原有的代码上添加一种新产品的生产,如“日本苹果”,具体的代码如下:
package factory
import "fmt"
type Fruit interface {
Show()
}
type Apple struct {
}
type Banana struct{}
type Pear struct{}
func (a *Apple) Show() {
println("我是苹果")
}
func (b *Banana) Show() {
println("我是香蕉")
}
func (p *Pear) Show() {
println("我是梨")
}
type FruitFactory interface {
CreateFruit() Fruit
}
type AppleFactory struct {
}
type PearFactory struct {
}
type BananaFactory struct {
}
func (applefac *AppleFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &Apple{}
return fruit
}
func (pearfac *PearFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &Pear{}
return fruit
}
func (bananafac *BananaFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &Banana{}
return fruit
}
// (+) 新增一个"日本苹果"
type JapanApple struct {
}
type JapanAppleFactory struct{}
func (jp *JapanApple) Show() {
fmt.Println("我是日本苹果")
}
func (jpapple *JapanAppleFactory) CreateFruit() Fruit {
var fruit Fruit
fruit = &JapanApple{}
return fruit
}
func main() {
var applefactory FruitFactory
applefactory = new(AppleFactory)
apple := applefactory.CreateFruit()
apple.Show()
var pearfactory FruitFactory
pearfactory = new(PearFactory)
pear := pearfactory.CreateFruit()
pear.Show()
var bananafactory FruitFactory
bananafactory = new(BananaFactory)
banana := bananafactory.CreateFruit()
banana.Show()
var jpapplefactory FruitFactory
jpapplefactory = new(JapanAppleFactory)
jpapple := jpapplefactory.CreateFruit()
jpapple.Show()
}
可以看见,新增的基本类“日本苹果”,和“具体的工厂” 均没有改动之前的任何代码。完全符合开闭原则思想。新增的功能不会影响到之前的已有的系统稳定性。
工厂方法模式的优缺点优点:
- 不需要记住具体类名,甚至连具体参数都不用记忆。
- 实现了对象创建和使用的分离。
- 系统的可扩展性也就变得非常好,无需修改接口和原类。
4.对于新产品的创建,符合开闭原则。
缺点:
- 增加系统中类的个数,复杂度和理解度增加。
- 增加了系统的抽象性和理解难度。
适用场景:
- 客户端不知道它所需要的对象的类。
- 抽象工厂类通过其子类来指定创建哪个对象。
2.1.4 抽象工厂方法模式
工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。因此,可以考虑将一些相关的产品组成一个“产品族”,由同一个工厂来统一生产,这就是本文将要学习的抽象工厂模式的基本思想。
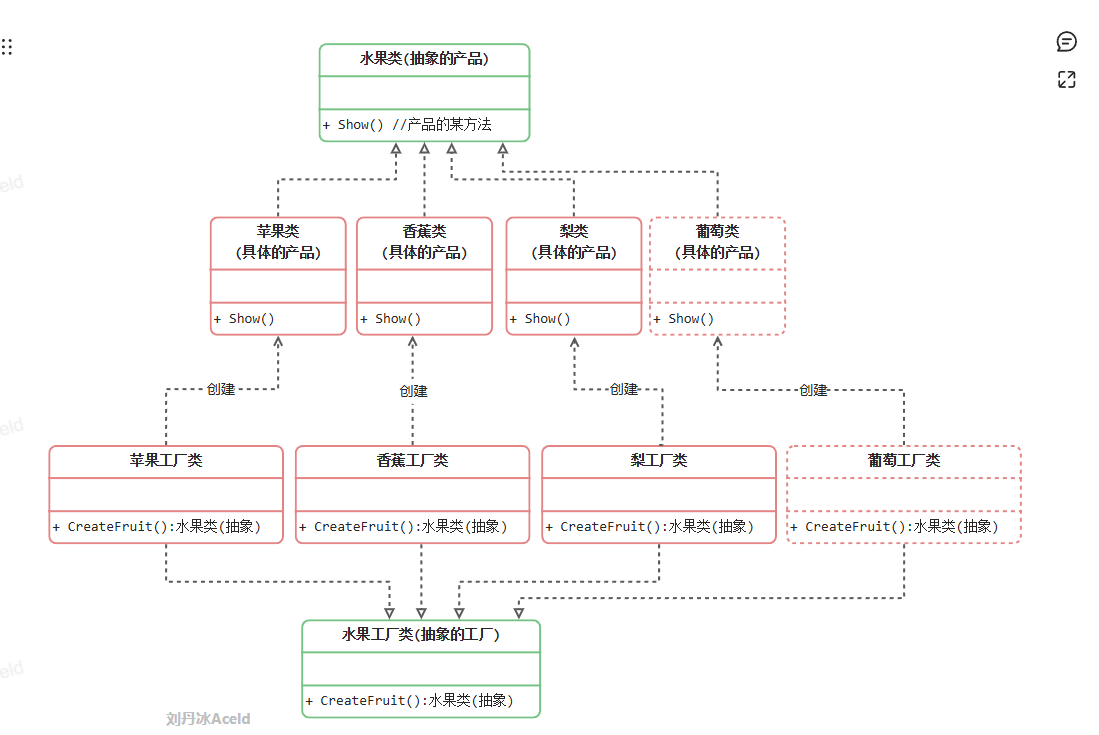
从工厂方法模式可以看出来:
(1)当添加一个新产品的时候,比如葡萄,虽然不用修改代码,但是需要添加大量的类,而且还需要添加相对的工厂。(系统开销,维护成本)
(2)如果使用同一地域的水果(日本苹果,日本香蕉,日本梨),那么需要分别创建具体的工厂,如果选择出现失误,将会造成混乱,虽然可以加一些约束,但是代码实现变得复杂。
所以“抽象工厂方法模式”引出了“产品族”和“产品等级结构”概念,其目的是为了更加高效的生产同一个产品组产品。
产品族与产品等级结构
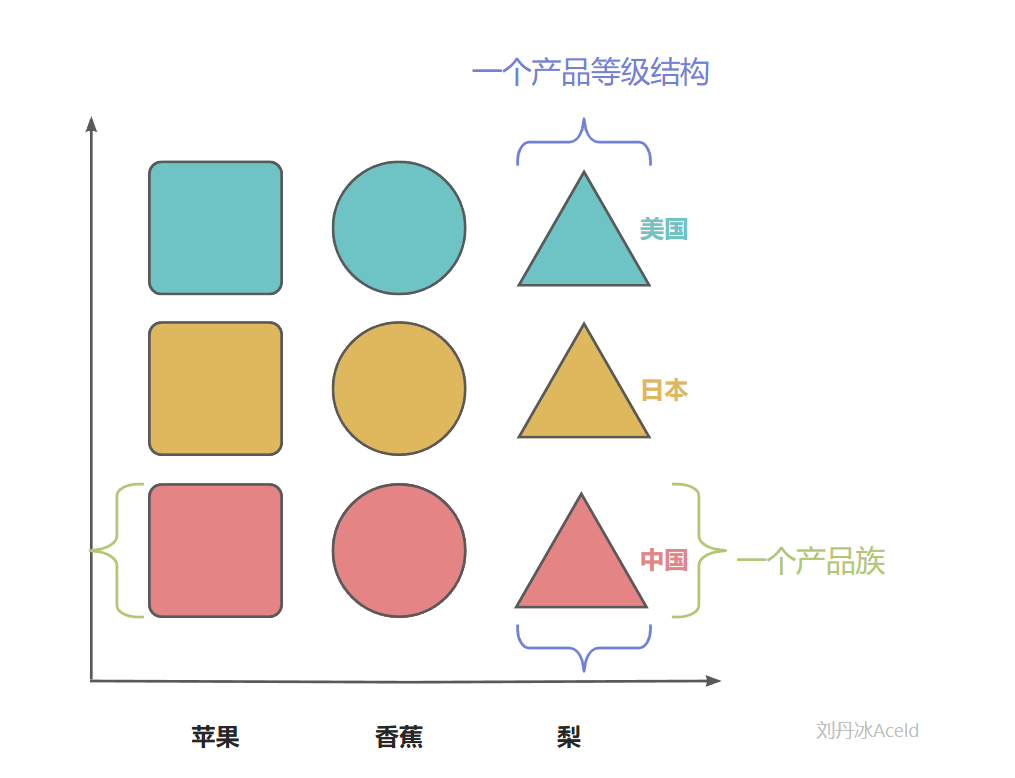
上图表示“产品族”和“产品登记结构”的关系。
产品族:具有同一个地区、同一个厂商、同一个开发包、同一个组织模块等,但是具备不同特点或功能的产品集合,称之为是一个产品族。
产品等级结构:具有相同特点或功能,但是来自不同的地区、不同的厂商、不同的开发包、不同的组织模块等的产品集合,称之为是一个产品等级结构。
当程序中的对象可以被划分为产品族和产品等级结构之后,那么“抽象工厂方法模式”才可以被适用。
“抽象工厂方法模式”是针对“产品族”进行生产产品,具体如下图所示。
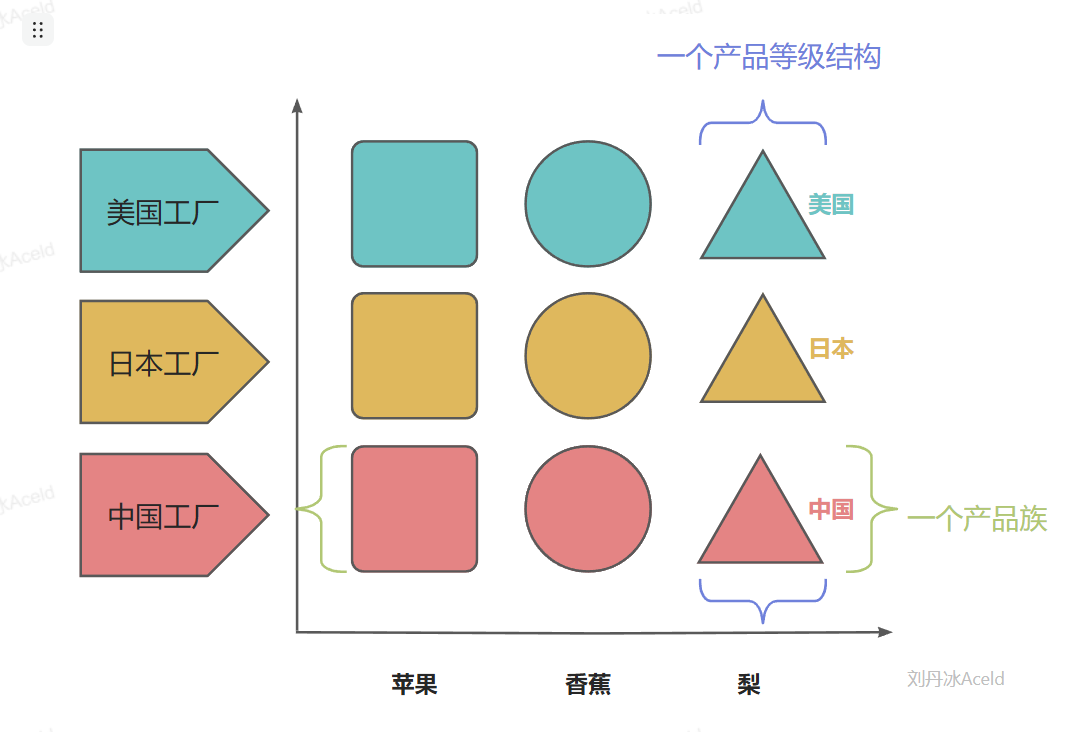
抽象工厂模式的角色和职责
抽象工厂(Abstract Factory)角色:它声明了一组用于创建一族产品的方法,每一个方法对应一种产品。
具体工厂(Concrete Factory)角色:它实现了在抽象工厂中声明的创建产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中。
抽象产品(Abstract Product)角色:它为每种产品声明接口,在抽象产品中声明了产品所具有的业务方法。
具体产品(Concrete Product)角色:它定义具体工厂生产的具体产品对象,实现抽象产品接口中声明的业务方法。
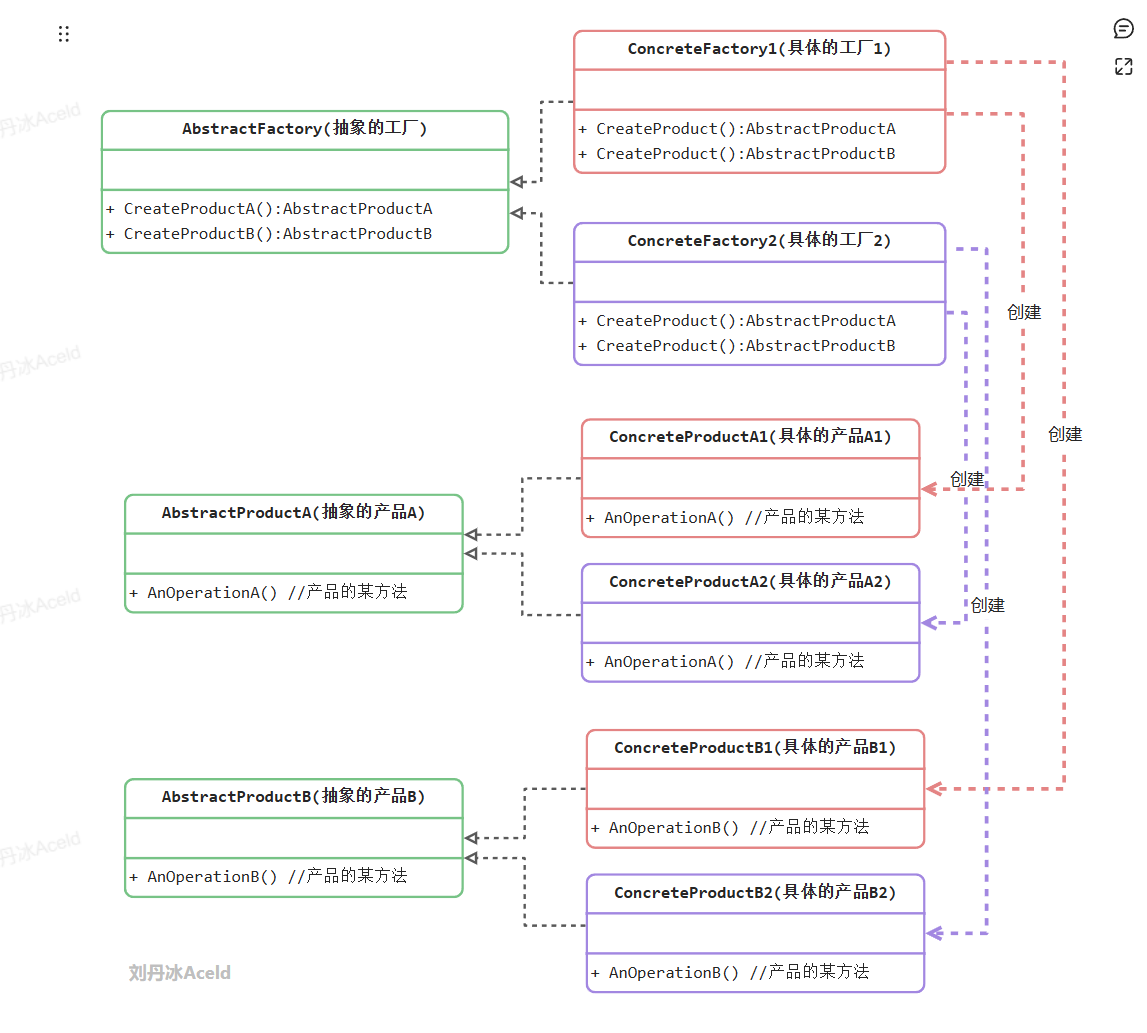
可以看出来具体的工厂1,只负责生成具体的产品A1和B1,具体的工厂2,只负责生成具体的产品A2和B2。
“工厂1、A1、B1”为一组,是一个产品族, “工厂2、A2、B2”为一组,也是一个产品族。
抽象工厂方法模式的实现
package abstractfactory
import "fmt"
type FruitFactory interface {
CreateApple() Apple
CreateBanana() Banana
CreatePear() Pear
}
type ChinaFruitFactory struct{}
type JapanFruitFactory struct{}
type AmericaFruitFactory struct{}
func (china *ChinaFruitFactory) CreateApple() Apple {
apple := new(ChinaApple)
return apple
}
func (china *ChinaFruitFactory) CreateBanana() Banana {
banana := new(ChinaBanana)
return banana
}
func (china *ChinaFruitFactory) CreatePear() Pear {
pear := new(ChinaPear)
return pear
}
func (japan *JapanFruitFactory) CreateApple() Apple {
apple := new(JapanApple)
return apple
}
func (japan *JapanFruitFactory) CreateBanana() Banana {
banana := new(JapanBanana)
return banana
}
func (japan *JapanFruitFactory) CreatePear() Pear {
pear := new(JapanPear)
return pear
}
func (america *AmericaFruitFactory) CreateApple() Apple {
apple := new(AmericaApple)
return apple
}
func (america *AmericaFruitFactory) CreateBanana() Banana {
banana := new(AmericaBanana)
return banana
}
func (america *AmericaFruitFactory) CreatePear() Pear {
pear := new(AmericaPear)
return pear
}
type Apple interface{ ShowApple() }
type Banana interface{ ShowBanana() }
type Pear interface{ ShowPear() }
type ChinaApple struct{}
type ChinaBanana struct{}
type ChinaPear struct{}
type JapanApple struct{}
type JapanBanana struct{}
type JapanPear struct{}
type AmericaApple struct{}
type AmericaBanana struct{}
type AmericaPear struct{}
func (chinaApple *ChinaApple) ShowApple() {
fmt.Println("我是中国苹果")
}
func (chinaBanana *ChinaBanana) ShowBanana() {
fmt.Println("我是中国香蕉")
}
func (chinaPear *ChinaPear) ShowPear() {
fmt.Println("我是中国梨")
}
func (japanApple *JapanApple) ShowApple() {
fmt.Println("我是日本苹果")
}
func (japanBanana *JapanBanana) ShowBanana() {
fmt.Println("我是日本香蕉")
}
func (japanPear *JapanPear) ShowPear() {
fmt.Println("我是日本梨")
}
func (americaApple *AmericaApple) ShowApple() {
fmt.Println("我是美国苹果")
}
func (americaBanana *AmericaBanana) ShowBanana() {
fmt.Println("我是美国香蕉")
}
func (americaPear *AmericaPear) ShowPear() {
fmt.Println("我是美国梨")
}
func main() {
chinaFactory := &ChinaFruitFactory{}
japanFactory := &JapanFruitFactory{}
americaFactory := &AmericaFruitFactory{}
chinaApple := chinaFactory.CreateApple()
chinaApple.ShowApple()
japanBanana := japanFactory.CreateBanana()
japanBanana.ShowBanana()
americaPear := americaFactory.CreatePear()
americaPear.ShowPear()
}
这段代码是使用Go语言实现的一个抽象工厂模式的例子。在这个例子中,我们定义了一个FruitFactory接口,该接口声明了三个方法:CreateApple(), CreateBanana(), 和 CreatePear()。每个方法返回特定类型的水果实例。
具体实现的工厂有ChinaFruitFactory, JapanFruitFactory, 和 AmericaFruitFactory,它们都实现了FruitFactory接口,并分别创建各自国家的苹果、香蕉和梨。
每种水果都有一个接口定义(Apple, Banana, Pear),以及具体的实现类(例如ChinaApple, JapanApple, AmericaApple等)。这些具体的水果类实现了各自的展示方法,如ShowApple()。
因此,从设计模式的角度来看,这段代码确实实现了抽象工厂模式。抽象工厂模式提供了一个接口,用于创建一系列相关或相互依赖的对象,而无需指定它们具体的类。在这个例子中,每个工厂可以创建一组相关的水果对象(苹果、香蕉和梨),并且可以根据需要选择不同的工厂来创建不同地区的产品。
为了完整这个示例并验证其功能,你可以添加一些调用代码到main()函数中,比如创建一个工厂实例并使用它来生成各种水果对象。下面是一个简单的示例:
这样的代码将会输出每个工厂创建的水果的信息。
2.1.5 建造者模式
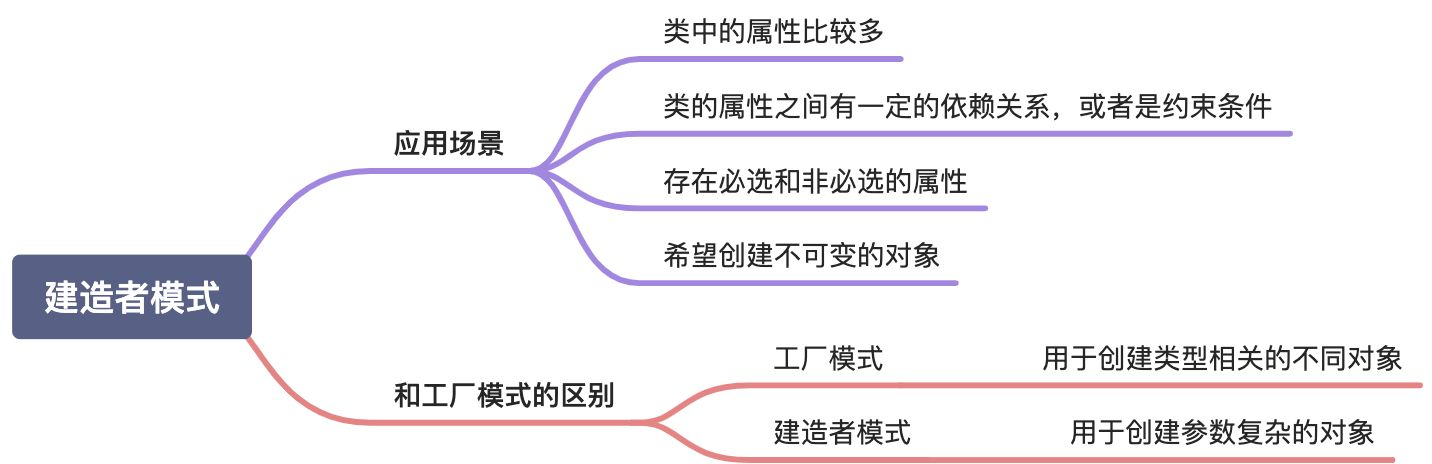
建造者模式(Builder Pattern),又叫生成器模式,将复杂对象的创建过程和对象本身进行抽象和分离,使得创建过程可以重用并创建多个不同表现的对象。
优点:
-
各个具体的建造者相互独立,有利于系统的扩展;
-
客户端不必知道产品内部组成的细节,便于控制细节风险。
缺点:1. 产品的创建过程相同才能重用,有一定的局限性;
- 产品的内部创建过程变化。
建造者模式结构
建造者模式有4个角色:
- 产品角色(Product):由具体建造者来实现各个创建步骤的业务逻辑;
- 抽象建造者(Abstract Builder):可以是接口和抽象类,通常会定义一个方法来创建复杂产品,一般命名为
build; - 具体建造者(Concrete Builder):实现抽象建造者中定义的创建步骤逻辑,完成复杂产品的各个部件的具体创建方法
- 指挥者(Director):调用抽象建造者对象中的部件构造与组装方法,然后调用
build方法完成复杂对象的创建;
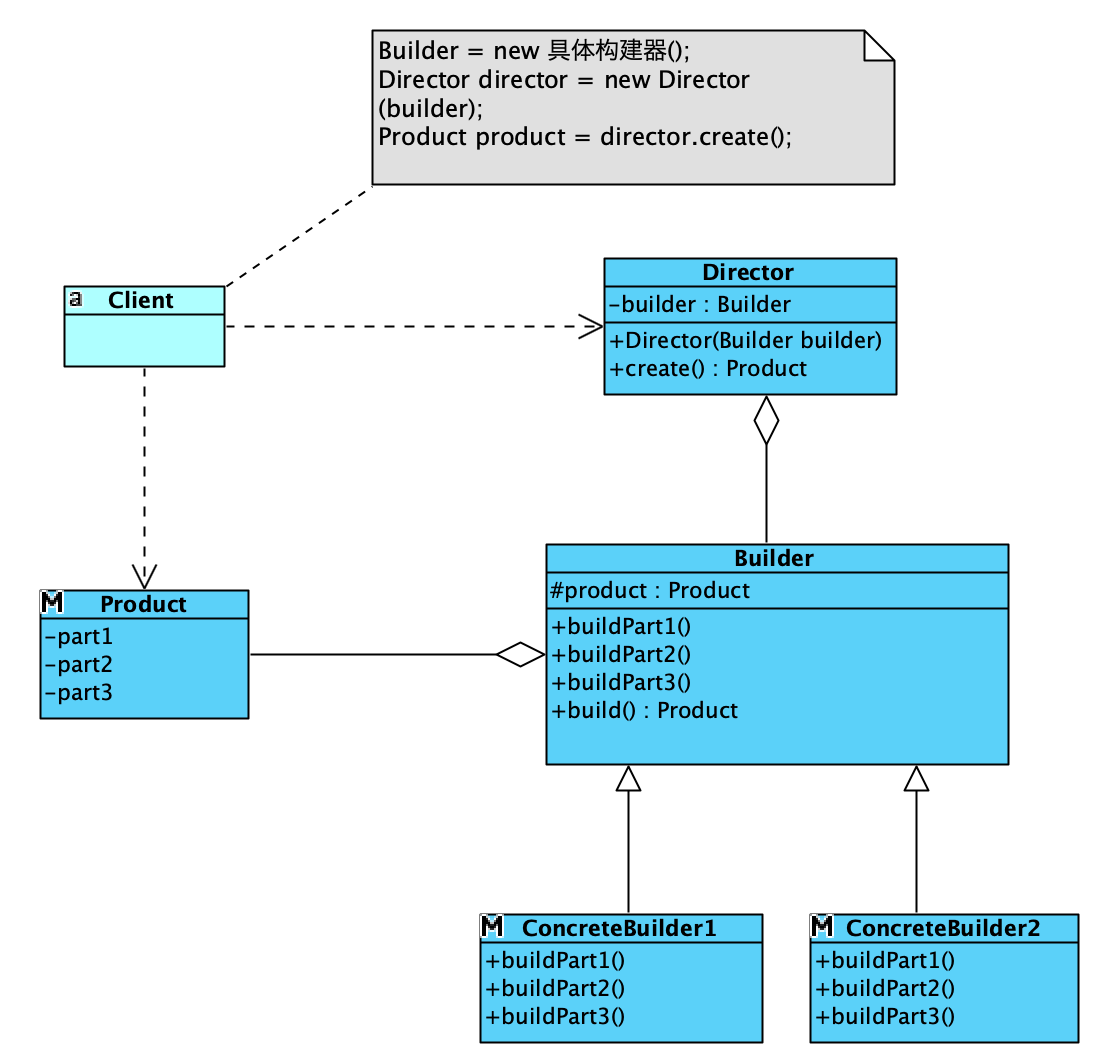
Director内部组合了抽象的Builder,用来构建产品;Client依赖Director创建产品,但是需要告诉它使用什么具体的Builder来创建,也就是会依赖具体的构建器.
抽象的Builder有两种形式:抽象类和接口。图中抽象的Builder为抽象类,其内部组合依赖了Product,并在build方法直接返回它;如果抽象Builder为接口,那么内部不会依赖Product,类结构上也会有一些变化,如下图所示:
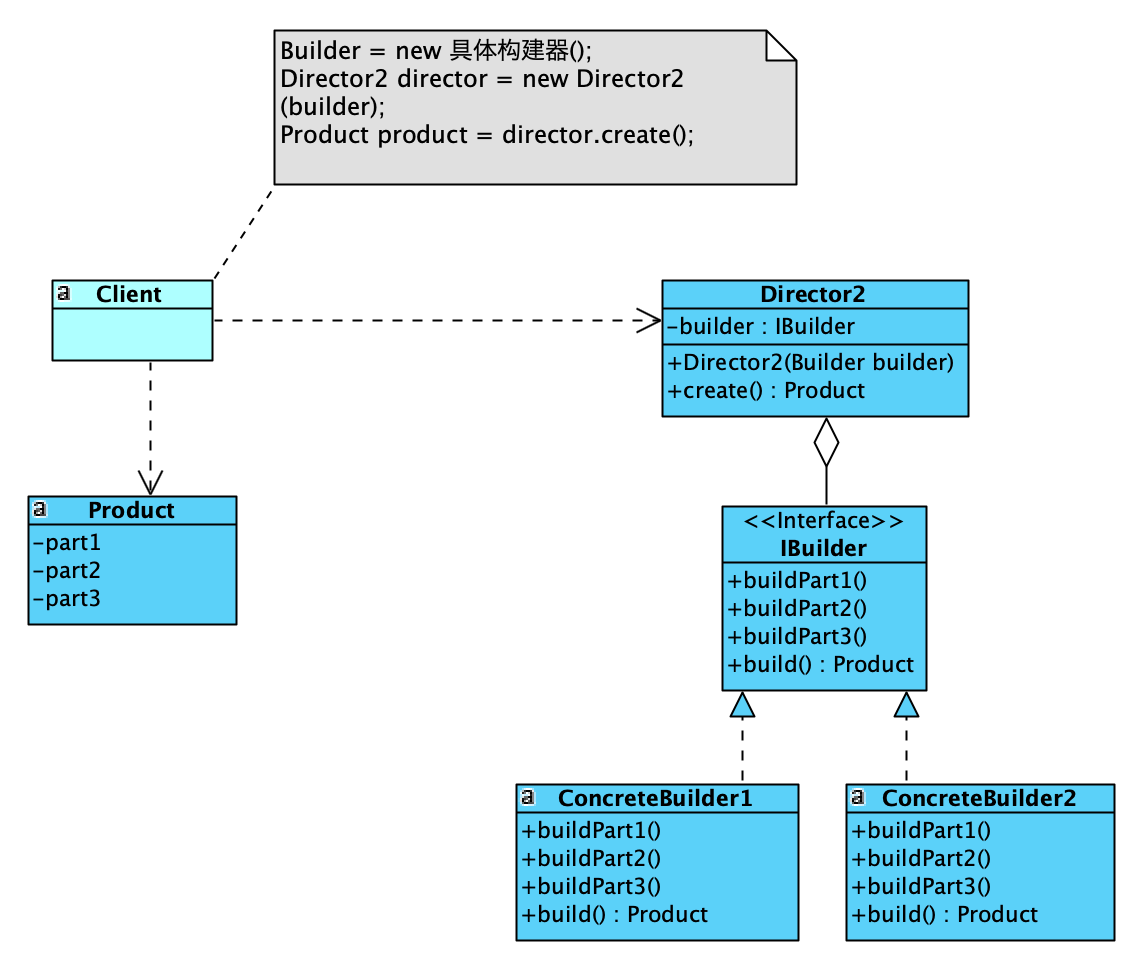
最显著的区别是,具体构建器需要实现build方法,返回具产品信息。
package main
import "fmt"
type Car struct {
//发动机
motor string
//变速箱
gearbox string
//底盘
chassis string
// 车架
frame string
}
type Builder interface {
BuildMotor() Builder
BuildGearbox() Builder
BuildChassis() Builder
BuildFrame() Builder
Build() *Car
}
type CarBuilder struct {
car Car
}
func (c *CarBuilder) BuildMotor() Builder {
c.car.motor = "Motor"
return c
}
func (c *CarBuilder) BuildGearbox() Builder {
c.car.gearbox = "Gearbox"
return c
}
func (c *CarBuilder) BuildChassis() Builder {
c.car.chassis = "Chassis"
return c
}
func (c *CarBuilder) BuildFrame() Builder {
return c
}
func (c *CarBuilder) Build() *Car {
return &c.car
}
type Director struct {
builder Builder
}
func (d *Director) Construct() *Car {
d.builder.BuildFrame().BuildChassis().BuildMotor().BuildGearbox()
return d.builder.Build()
}
func main() {
var director Director = Director{
builder: new(CarBuilder),
}
car := director.Construct()
fmt.Printf("Car built with: %s, %s, %s, %s\n", car.frame, car.chassis, car.motor, car.gearbox)
}
建造者模式(Builder Pattern)在实际生产中有很多应用场景,尤其适用于构建复杂对象。这些对象通常由多个部分组成,并且这些部分可能具有不同的配置和创建顺序。以下是几个实际生产中使用建造者模式的例子,并附有Go的代码示例
配置复杂对象
在Web应用程序中,配置复杂的请求或响应对象是一个常见的需求。建造者模式可以用于构建配置复杂的HTTP请求。
package main
import (
"bytes"
"fmt"
"io"
"net/http"
"os"
"time"
)
type HTTPRequestBuilder interface {
SetMethod(method string) HTTPRequestBuilder
SetURL(url string) HTTPRequestBuilder
SetHeader(headers map[string]string) HTTPRequestBuilder
SetBody(body []byte) HTTPRequestBuilder
SetTimeout(duration time.Duration) HTTPRequestBuilder
Build() (*http.Request, error)
}
type ConcreteHTTPRequestBuilder struct {
method string
url string
headers map[string]string
body []byte
timeout time.Duration
}
func (b *ConcreteHTTPRequestBuilder) SetMethod(method string) HTTPRequestBuilder {
validMethods := map[string]bool{
"GET": true,
"POST": true,
"PUT": true,
"DELETE": true,
"PATCH": true,
"OPTIONS": true,
"HEAD": true,
}
// 验证 HTTP 方法是否合法
if !validMethods[method] {
panic("Invalid HTTP method: " + method)
}
b.method = method
return b
}
func (b *ConcreteHTTPRequestBuilder) SetURL(url string) HTTPRequestBuilder {
if url == "" {
panic("URL cannot be empty")
}
b.url = url
return b
}
func (b *ConcreteHTTPRequestBuilder) SetHeader(headers map[string]string) HTTPRequestBuilder {
if headers == nil {
headers = make(map[string]string)
}
b.headers = headers
return b
}
func (b *ConcreteHTTPRequestBuilder) SetBody(body []byte) HTTPRequestBuilder {
b.body = body
return b
}
func (b *ConcreteHTTPRequestBuilder) SetTimeout(duration time.Duration) HTTPRequestBuilder {
b.timeout = duration
return b
}
func (b *ConcreteHTTPRequestBuilder) Build() (*http.Request, error) {
// 构建 HTTP 请求,并将 body 转换为 io.Reader 类型
req, err := http.NewRequest(b.method, b.url, bytes.NewBuffer(b.body))
if err != nil {
return nil, err
}
// 设置请求头
for k, v := range b.headers {
req.Header.Set(k, v)
}
return req, nil
}
type HTTPRequestDirector struct {
builder HTTPRequestBuilder
timeout time.Duration
}
func (d *HTTPRequestDirector) NewHTTPRequestBuilder(method string, url string, header map[string]string, body []byte) (*http.Request, error) {
req, err := d.builder.SetMethod(method).SetURL(url).SetHeader(header).SetBody(body).Build()
if err != nil {
return nil, err
}
return req, nil
}
func (d *HTTPRequestDirector) DoRequest(req *http.Request) (*http.Response, string, error) {
client := &http.Client{Timeout: d.timeout}
resp, err := client.Do(req)
if err != nil {
return nil, "", err
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
return nil, "", err
}
return resp, string(body), nil
}
func main() {
// 创建 HTTP 请求的指导者
director := HTTPRequestDirector{
builder: &ConcreteHTTPRequestBuilder{},
timeout: 5 * time.Second,
}
// 构建一个 POST 请求,带上请求体
body := []byte(`{"name":"John","age":30}`)
headers := map[string]string{
"Content-Type": "application/json",
}
req, err := director.NewHTTPRequestBuilder("POST", "https://httpbin.org/post", headers, body)
if err != nil {
fmt.Printf("Error creating request: %v\n", err)
os.Exit(1)
}
// 发送请求并获取响应
resp, bodyStr, err := director.DoRequest(req)
if err != nil {
fmt.Printf("Error making request: %v\n", err)
os.Exit(1)
}
// 打印响应状态和响应体
fmt.Printf("Response status: %s\n", resp.Status)
fmt.Printf("Response body: %s\n", bodyStr)
}
2.1.6 原型模式
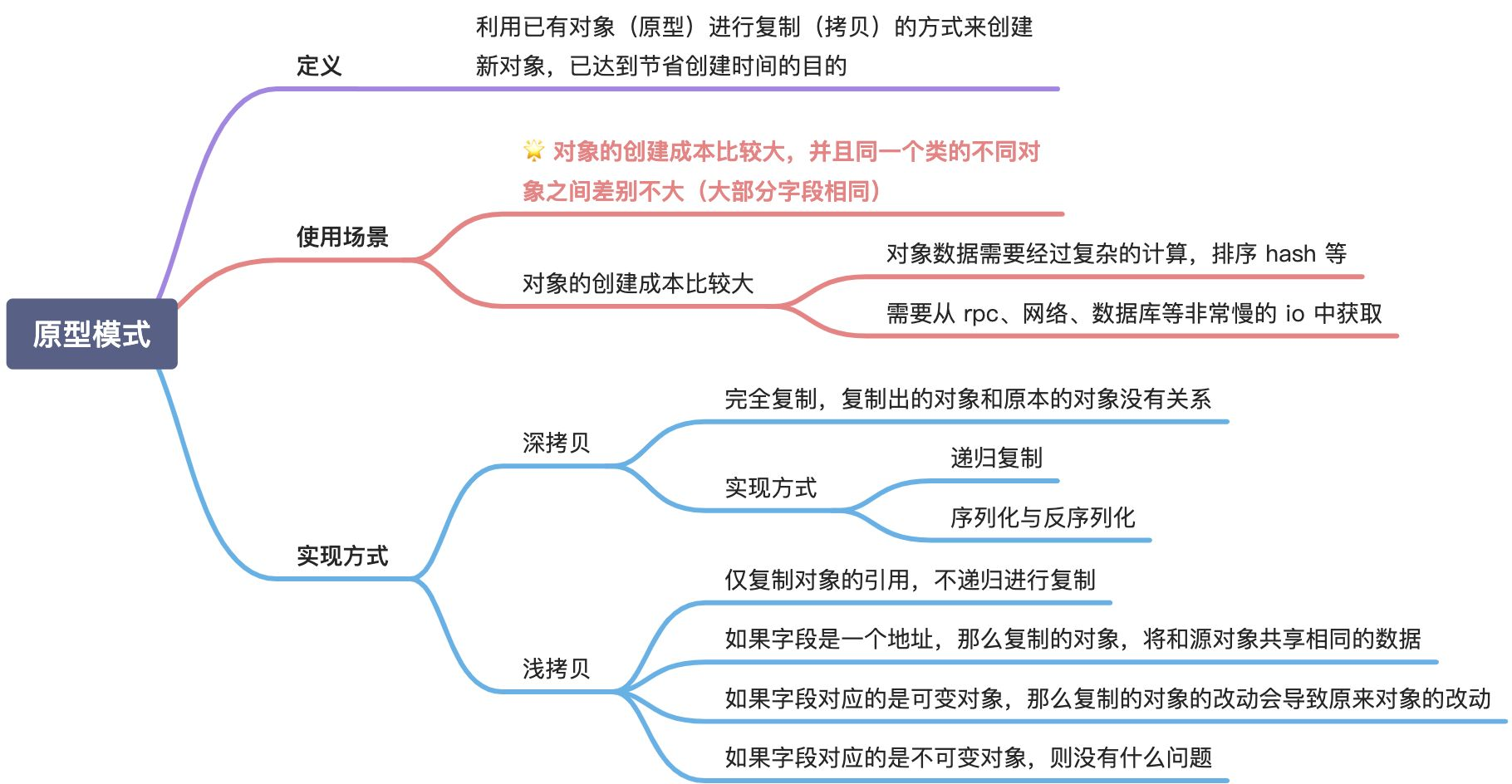
原型模式(Prototype Pattern),它的基本思想是:创建一个对象实例作为原型,然后不断的复制(或者叫克隆)这个原型对象来创建该对象的新实例,而不是反复的使用构造函数来实例化对象。
原型模式创建对象,调用者无需关心对象创建细节,只需要调用复制方法,即可得到与原型对象属性相同的新实例,方便而且高效。
原型模式的结构如下图所示:
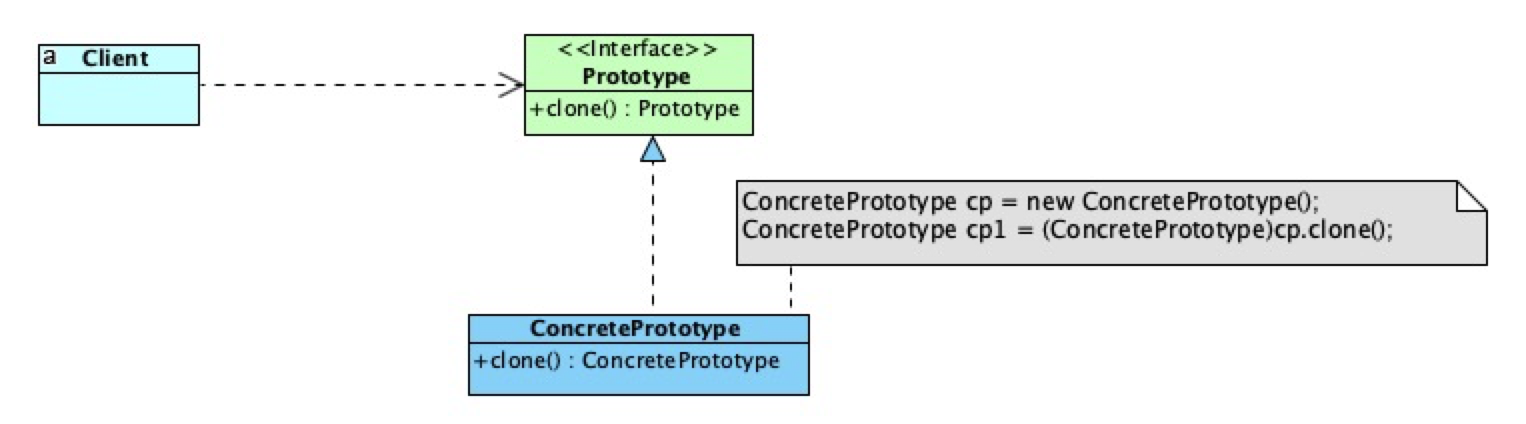
浅拷贝和深拷贝
基本类型
基本类型是 Go 语言自带的类型,比如 数值、浮点、字符串、布尔、数组 及 错误 类型,他们本质上是原始类型,也就是不可改变的,所以对他们进行操作,一般都会返回一个新创建的值,所以把这些值传递给函数时,其实传递的是一个值的副本。
引用类型
引用类型和原始的基本类型恰恰相反,它的修改可以影响到任何引用到它的变量。在 Go 语言中,引用类型有 切片(slice)、字典(map)、接口(interface)、函数(func) 以及 通道(chan) 。
引用类型之所以可以引用,是因为我们创建引用类型的变量,其实是一个标头值,标头值里包含一个指针,指向底层的数据结构,当我们在函数中传递引用类型时,其实传递的是这个标头值的副本,它所指向的底层结构并没有被复制传递,这也是引用类型传递高效的原因。
本质上,我们可以理解函数的传递都是值传递,只不过引用类型传递的是一个指向底层数据的指针,所以我们在操作的时候,可以修改共享的底层数据的值,进而影响到所有引用到这个共享底层数据的变量。
https://www.cnblogs.com/52php/p/6727082.html
浅拷贝是指创建一个新对象,这个新对象拥有原对象的部分属性值。对于值类型的数据,直接复制其值;对于引用类型的数据,只复制引用,不复制引用的对象本身。这意味着浅拷贝后的新对象和原对象共享相同的引用对象。
深拷贝是指创建一个新对象,并且递归地复制所有引用对象。这意味着深拷贝后的新对象和原对象完全独立,修改新对象不会影响原对象。
结构体的拷贝行为取决于字段的类型
当你直接复制结构体时,Go 会逐字段进行值拷贝,对于值类型字段(例如 int、string、float 等),它们会被独立复制,而对于引用类型字段(如切片、映射、指针等),它们会被拷贝为引用,即会指向同一个底层数据。
深拷贝意味着不仅仅是结构体本身的拷贝,还需要对结构体中所有的引用类型字段(如切片、映射、指针等)进行递归拷贝,以确保每个引用类型字段的底层数据都被独立复制。
我们先用浅拷贝简单实现一下原型模式
https://www.cnblogs.com/52php/p/6727082.html
Golang基本类型和引用类型
package main
import (
"fmt"
"unsafe"
)
// Document 接口定义了克隆方法和获取信息方法
type Document interface {
Clone() Document
GetInfo() string
}
// TextDocument 是一个包含引用类型的文档结构体
type TextDocument struct {
Content string
Tags []string
}
// Clone 方法实现浅拷贝
func (t *TextDocument) Clone() Document {
clon := *t
return &clon
}
// GetInfo 方法返回文档内容
func (t *TextDocument) GetInfo() string {
return t.Content
}
func main() {
textDoc := &TextDocument{
Content: "Hello World!",
Tags: []string{"golang", "programming"},
}
// 克隆文档
clonedDoc := textDoc.Clone().(*TextDocument)
fmt.Printf("Original Document Pointer: %p\n", &textDoc)
fmt.Printf("Cloned Document Pointer: %p\n", &clonedDoc)
fmt.Println()
// 修改克隆对象的 Tags
clonedDoc.Tags[0] = "cloned"
fmt.Println("Original Document Tags:", textDoc.Tags) // 输出: [cloned programming]
fmt.Println("Cloned Document Tags:", clonedDoc.Tags) // 输出: [cloned programming]
// 检查 Tags 切片的底层数组地址
/*
浅拷贝和深拷贝的一些微妙之处。在Go中,当我们进行浅拷贝时,如果结构体包含了切片(引用类型),
新的结构体和原始结构体的切片字段将引用同一个底层数组。尽管切片本身的地址不同,它们指向的底层数组是相同的。
*/
fmt.Printf("Original Document Tags Pointer: %p\n", &textDoc.Tags)
fmt.Printf("Original Document Tags Pointer: %p\n", &clonedDoc.Tags)
fmt.Println()
fmt.Printf("Original Document Tags Array Pointer: %p\n", unsafe.Pointer(&textDoc.Tags[0]))
fmt.Printf("Cloned Document Tags Array Pointer: %p\n", unsafe.Pointer(&clonedDoc.Tags[0]))
}
package main
import (
"fmt"
"unsafe"
)
// Document 接口定义了克隆方法和获取信息方法
type Document interface {
Clone() Document
GetInfo() string
}
// TextDocument 是一个包含引用类型的文档结构体
type TextDocument struct {
Content string
Tags []string
}
// Clone 方法实现浅拷贝
func (t *TextDocument) Clone() Document {
clon := *t
return &clon
}
// GetInfo 方法返回文档内容
func (t *TextDocument) GetInfo() string {
return t.Content
}
func main() {
textDoc := &TextDocument{
Content: "Hello World!",
Tags: []string{"golang", "programming"},
}
// 克隆文档
clonedDoc := textDoc.Clone().(*TextDocument)
fmt.Printf("Original Document Pointer: %p\n", &textDoc)
fmt.Printf("Cloned Document Pointer: %p\n", &clonedDoc)
fmt.Println()
// 修改克隆对象的 Tags
clonedDoc.Tags[0] = "cloned"
fmt.Println("Original Document Tags:", textDoc.Tags) // 输出: [cloned programming]
fmt.Println("Cloned Document Tags:", clonedDoc.Tags) // 输出: [cloned programming]
// 检查 Tags 切片的底层数组地址
/*
浅拷贝和深拷贝的一些微妙之处。在Go中,当我们进行浅拷贝时,如果结构体包含了切片(引用类型),
新的结构体和原始结构体的切片字段将引用同一个底层数组。尽管切片本身的地址不同,它们指向的底层数组是相同的。
*/
fmt.Printf("Original Document Tags Pointer: %p\n", &textDoc.Tags)
fmt.Printf("Original Document Tags Pointer: %p\n", &clonedDoc.Tags)
fmt.Println()
fmt.Printf("Original Document Tags Array Pointer: %p\n", unsafe.Pointer(&textDoc.Tags[0]))
fmt.Printf("Cloned Document Tags Array Pointer: %p\n", unsafe.Pointer(&clonedDoc.Tags[0]))
}
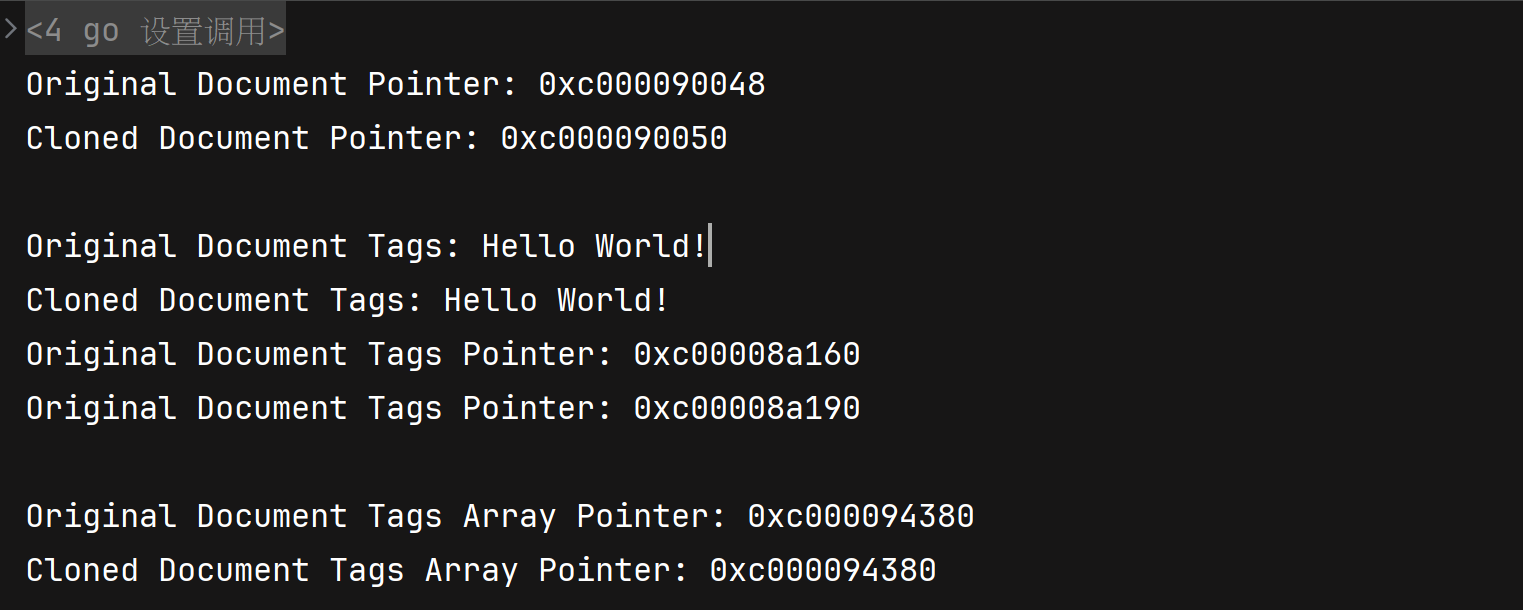
根据输出结果我们能看到
其实在golang中,浅拷贝我们没必要去写这个clone函数,因为直接赋值就已经实现了浅拷贝的效果
直接赋值和浅拷贝的区别
直接赋值:
- 当你直接赋值一个结构体时,Go会对所有字段进行浅拷贝。
- 对于引用类型(如切片、指针、映射等),直接赋值会复制引用,所以原对象和新对象将共享相同的底层数据。
使用
Clone 方法的浅拷贝:
- 使用
Clone 方法进行浅拷贝时,如果你在方法内部对结构体进行赋值操作(即clon := *t),Go会创建一个新结构体,但所有引用类型的字段仍然共享相同的底层数据。可以在下面的代码中得到验证
package main import ( "fmt" "unsafe" ) // Document 接口定义了克隆方法和获取信息方法 type Document interface { Clone() Document GetInfo() string } // TextDocument 是一个包含引用类型的文档结构体 type TextDocument struct { Content string Tags []string } // Clone 方法实现浅拷贝 func (t *TextDocument) Clone() Document { clon := *t return &clon } // GetInfo 方法返回文档内容 func (t *TextDocument) GetInfo() string { return t.Content } func main() { textDoc := &TextDocument{ Content: "Hello World!", Tags: []string{"golang", "programming"}, } // 克隆文档 //clonedDoc := textDoc.Clone().(*TextDocument) clonedDoc := textDoc fmt.Printf("Original Document Pointer: %p\n", &textDoc) fmt.Printf("Cloned Document Pointer: %p\n", &clonedDoc) fmt.Println() // 修改克隆对象的 Tags clonedDoc.Tags[0] = "cloned" fmt.Println("Original Document Tags:", textDoc.Tags) // 输出: [cloned programming] fmt.Println("Cloned Document Tags:", clonedDoc.Tags) // 输出: [cloned programming] // 检查 Tags 切片的底层数组地址 /* 浅拷贝和深拷贝的一些微妙之处。在Go中,当我们进行浅拷贝时,如果结构体包含了切片(引用类型), 新的结构体和原始结构体的切片字段将引用同一个底层数组。尽管切片本身的地址不同,它们指向的底层数组是相同的。 */ fmt.Printf("Original Document Tags Pointer: %p\n", &textDoc.Tags) fmt.Printf("Original Document Tags Pointer: %p\n", &clonedDoc.Tags) fmt.Println() fmt.Printf("Original Document Tags Array Pointer: %p\n", unsafe.Pointer(&textDoc.Tags[0])) fmt.Printf("Cloned Document Tags Array Pointer: %p\n", unsafe.Pointer(&clonedDoc.Tags[0])) }
深拷贝
深拷贝的两种方法:
- 序列化
- 反射
下面我们来分开讲这两种方式
序列化
package main
import (
"bytes"
"encoding/gob"
"fmt"
"unsafe"
)
// Document 接口定义了克隆方法和获取信息方法
type Document interface {
Clone() Document
GetInfo() string
}
// TextDocument 是一个包含引用类型的文档结构体
type TextDocument struct {
Content string
Tags []string
}
// Clone 方法实现深拷贝
func (t *TextDocument) Clone() Document {
var buf bytes.Buffer
enc := gob.NewEncoder(&buf)
dec := gob.NewDecoder(&buf)
// 编码原始对象
if err := enc.Encode(t); err != nil {
panic(err)
}
// 解码到新对象
cloned := &TextDocument{}
if err := dec.Decode(cloned); err != nil {
panic(err)
}
return cloned
}
// GetInfo 方法返回文档内容
func (t *TextDocument) GetInfo() string {
return t.Content
}
func main() {
textDoc := &TextDocument{
Content: "Hello World!",
Tags: []string{"golang", "programming"},
}
// 克隆文档
clonedDoc := textDoc.Clone().(*TextDocument)
fmt.Printf("Original Document Pointer: %p\n", &textDoc)
fmt.Printf("Cloned Document Pointer: %p\n", &clonedDoc)
fmt.Println()
// 修改克隆对象的 Tags
clonedDoc.Tags[0] = "cloned"
fmt.Println("Original Document Tags:", textDoc.Tags) // 输出: [golang programming]
fmt.Println("Cloned Document Tags:", clonedDoc.Tags) // 输出: [cloned programming]
// 检查 Tags 切片的底层数组地址
fmt.Printf("Original Document Tags Pointer: %p\n", &textDoc.Tags)
fmt.Printf("Original Document Tags Pointer: %p\n", &clonedDoc.Tags)
fmt.Println()
fmt.Printf("Original Document Tags Slice Pointer: %p\n", unsafe.Pointer(&textDoc.Tags[0]))
fmt.Printf("Cloned Document Tags Slice Pointer: %p\n", unsafe.Pointer(&clonedDoc.Tags[0]))
}
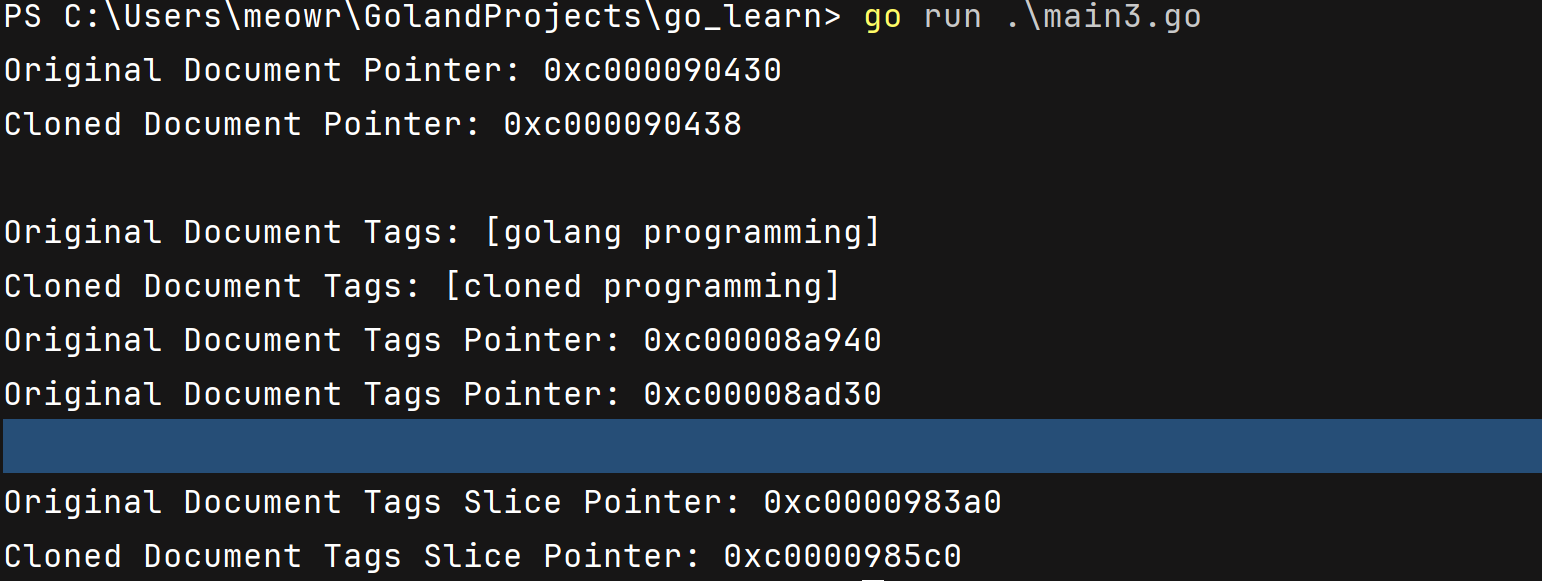
其实我们还可以单独把slice复制一份新的重新赋值
package main
import (
"fmt"
"unsafe"
)
// Document 接口定义了克隆方法和获取信息方法
type Document interface {
Clone() Document
GetInfo() string
}
// TextDocument 是一个包含引用类型的文档结构体
type TextDocument struct {
Content string
Tags []string
}
// Clone 方法实现深拷贝
func (t *TextDocument) Clone() Document {
newSlice := make([]string, len(t.Tags))
copy(newSlice, t.Tags)
clon := *t
clon.Tags = newSlice
return &clon
}
// GetInfo 方法返回文档内容
func (t *TextDocument) GetInfo() string {
return t.Content
}
func main() {
textDoc := &TextDocument{
Content: "Hello World!",
Tags: []string{"golang", "programming"},
}
// 克隆文档
clonedDoc := textDoc.Clone().(*TextDocument)
fmt.Printf("Original Document Pointer: %p\n", textDoc)
fmt.Printf("Cloned Document Pointer: %p\n", clonedDoc)
fmt.Println()
// 修改克隆对象的 Tags
clonedDoc.Tags[0] = "cloned"
fmt.Println("Original Document Tags:", textDoc.Tags) // 输出: [golang programming]
fmt.Println("Cloned Document Tags:", clonedDoc.Tags) // 输出: [cloned programming]
// 检查 Tags 切片的底层数组地址
fmt.Printf("Original Document Tags Pointer: %p\n", &textDoc.Tags)
fmt.Printf("Original Document Tags Pointer: %p\n", &clonedDoc.Tags)
fmt.Println()
fmt.Printf("Original Document Tags Array Pointer: %p\n", unsafe.Pointer(&textDoc.Tags[0]))
fmt.Printf("Cloned Document Tags Array Pointer: %p\n", unsafe.Pointer(&clonedDoc.Tags[0]))
}
反射法
package main
import (
"fmt"
"unsafe"
)
// Document 接口定义了克隆方法和获取信息方法
type Document interface {
Clone() Document
GetInfo() string
}
// TextDocument 是一个包含引用类型的文档结构体
type TextDocument struct {
Content string
Tags []string
}
// Clone 方法实现深拷贝
func (t *TextDocument) Clone() Document {
newSlice := make([]string, len(t.Tags))
copy(newSlice, t.Tags)
clon := *t
clon.Tags = newSlice
return &clon
}
// GetInfo 方法返回文档内容
func (t *TextDocument) GetInfo() string {
return t.Content
}
func main() {
textDoc := &TextDocument{
Content: "Hello World!",
Tags: []string{"golang", "programming"},
}
// 克隆文档
clonedDoc := textDoc.Clone().(*TextDocument)
fmt.Printf("Original Document Pointer: %p\n", textDoc)
fmt.Printf("Cloned Document Pointer: %p\n", clonedDoc)
fmt.Println()
// 修改克隆对象的 Tags
clonedDoc.Tags[0] = "cloned"
fmt.Println("Original Document Tags:", textDoc.Tags) // 输出: [golang programming]
fmt.Println("Cloned Document Tags:", clonedDoc.Tags) // 输出: [cloned programming]
// 检查 Tags 切片的底层数组地址
fmt.Printf("Original Document Tags Pointer: %p\n", &textDoc.Tags)
fmt.Printf("Original Document Tags Pointer: %p\n", &clonedDoc.Tags)
fmt.Println()
fmt.Printf("Original Document Tags Array Pointer: %p\n", unsafe.Pointer(&textDoc.Tags[0]))
fmt.Printf("Cloned Document Tags Array Pointer: %p\n", unsafe.Pointer(&clonedDoc.Tags[0]))
}
2.2 结构型模式
2.2.1 代理模式
Proxy模式又叫做代理模式,是构造型的设计模式之一,它可以为其他对象提供一种代理(Proxy)以控制对这个对象的访问。
所谓代理,是指具有与代理元(被代理的对象)具有相同的接口的类,客户端必须通过代理与被代理的目标类交互,而代理一般在交互的过程中(交互前后),进行某些特别的处理。
用一个日常可见的案例来理解“代理”的概念,如下图:
代理模式中的角色和职责
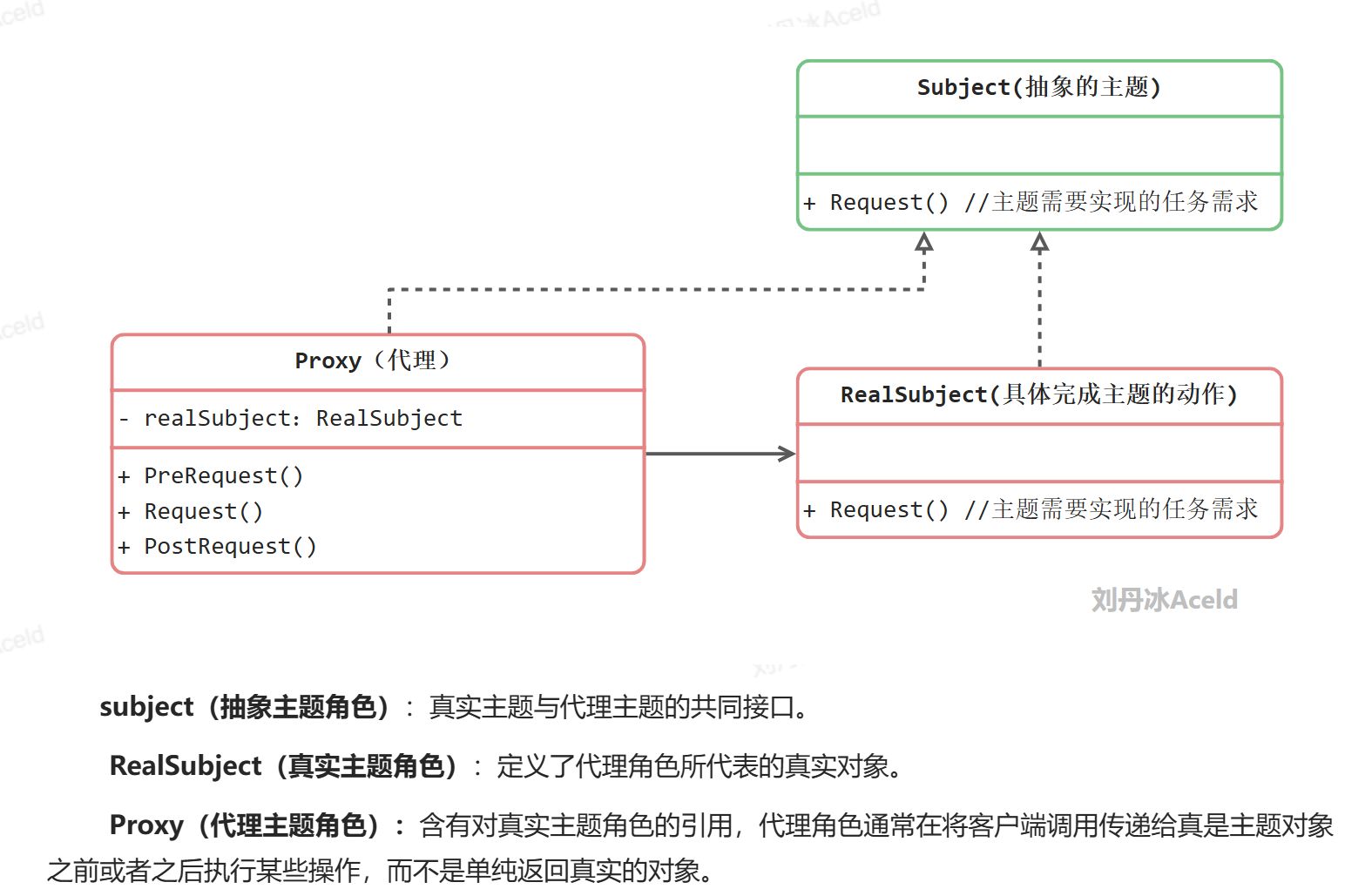
代理模式案例实现
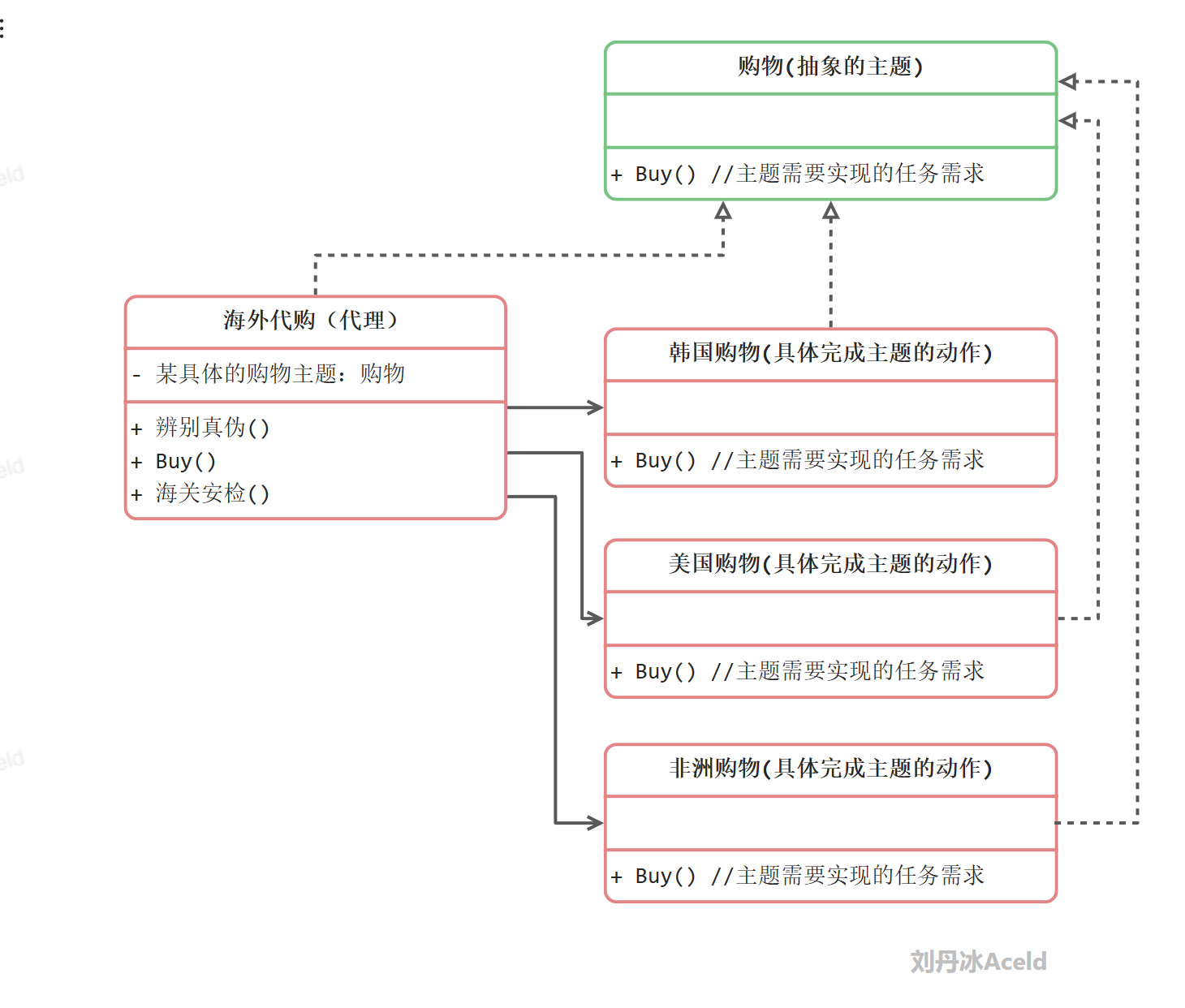
代码如下
package proxy
import "fmt"
type Buy interface {
Buy()
}
type BuyProxy struct {
buyer Buy
}
func (buy BuyProxy) PreBuy() {
fmt.Println("pre buy something")
}
func (buy BuyProxy) Buy() {
buy.PreBuy()
buy.buyer.Buy()
buy.PostBuy()
}
func (buy BuyProxy) PostBuy() {
fmt.Println("post buy something")
}
type BuyFromChina struct {
}
func (buy BuyFromChina) Buy() {
// buy something from china
fmt.Println("buy something from china")
}
type BuyFromAmerica struct {
}
func (buy BuyFromAmerica) Buy() {
fmt.Println("buy something from america")
}
type BuyFromJapan struct {
}
func (buy BuyFromJapan) Buy() {
fmt.Println("buy something from japan")
}
func BuyTest() {
buy := BuyProxy{buyer: BuyFromChina{}}
buy.Buy()
}
代理模式的优缺点
优点:
(1) 能够协调调用者和被调用者,在一定程度上降低了系统的耦合度。
(2) 客户端可以针对抽象主题角色进行编程,增加和更换代理类无须修改源代码,符合开闭原则,系统具有较好的灵活性和可扩展性。
缺点:
(1) 代理实现较为复杂。
2.2.2 装饰模式
装饰模式(Decorator Pattern):动态地给一个对象增加一些额外的职责,就增加对象功能来说,装饰模式比生成子类实现更为灵活。装饰模式是一种对象结构型模式。
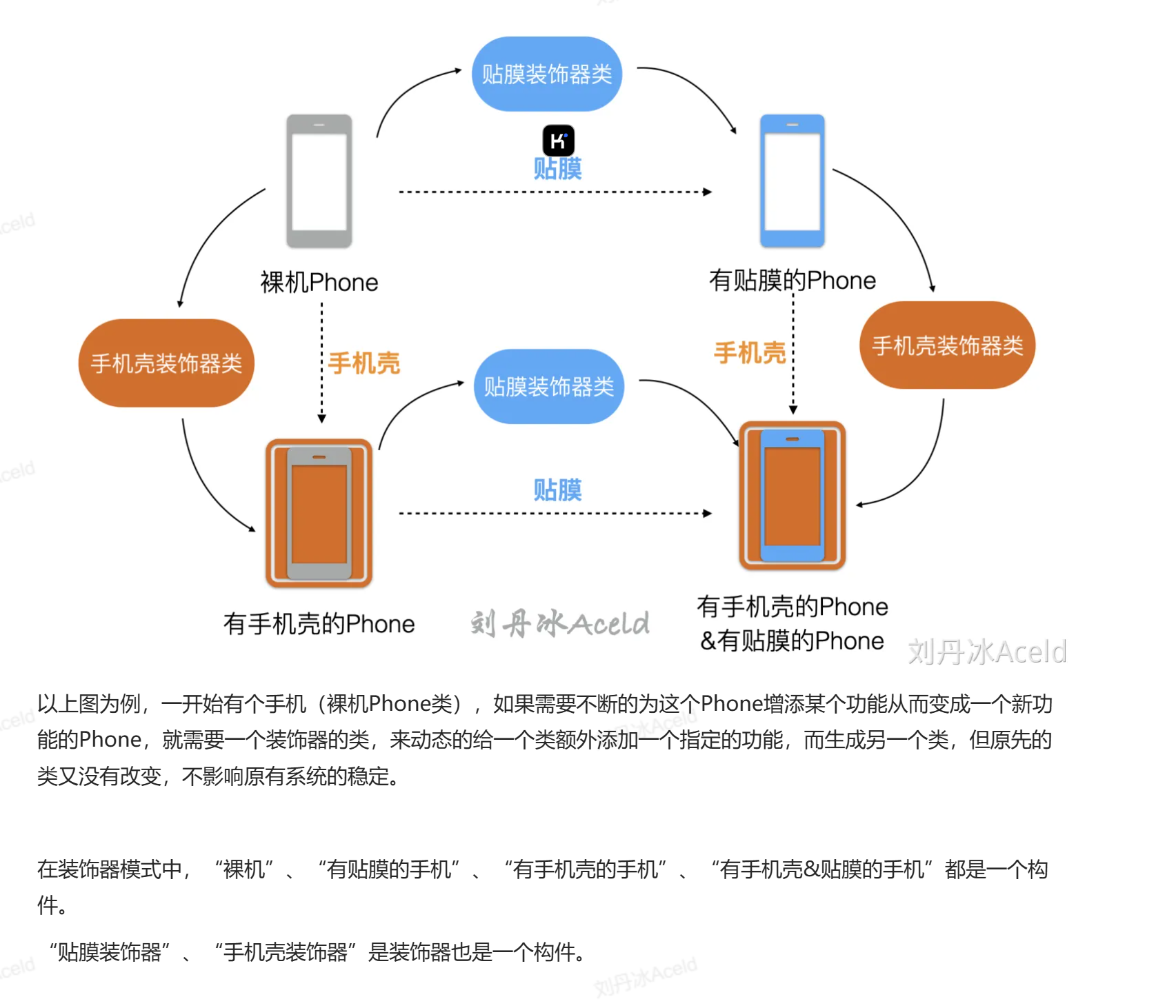
装饰模式中的角色和职责
Component(抽象构件):它是具体构件和抽象装饰类的共同父类,声明了在具体构件中实现的业务方法,它的引入可以使客户端以一致的方式处理未被装饰的对象以及装饰之后的对象,实现客户端的透明操作。
ConcreteComponent(具体构件):它是抽象构件类的子类,用于定义具体的构件对象,实现了在抽象构件中声明的方法,装饰器可以给它增加额外的职责(方法)。
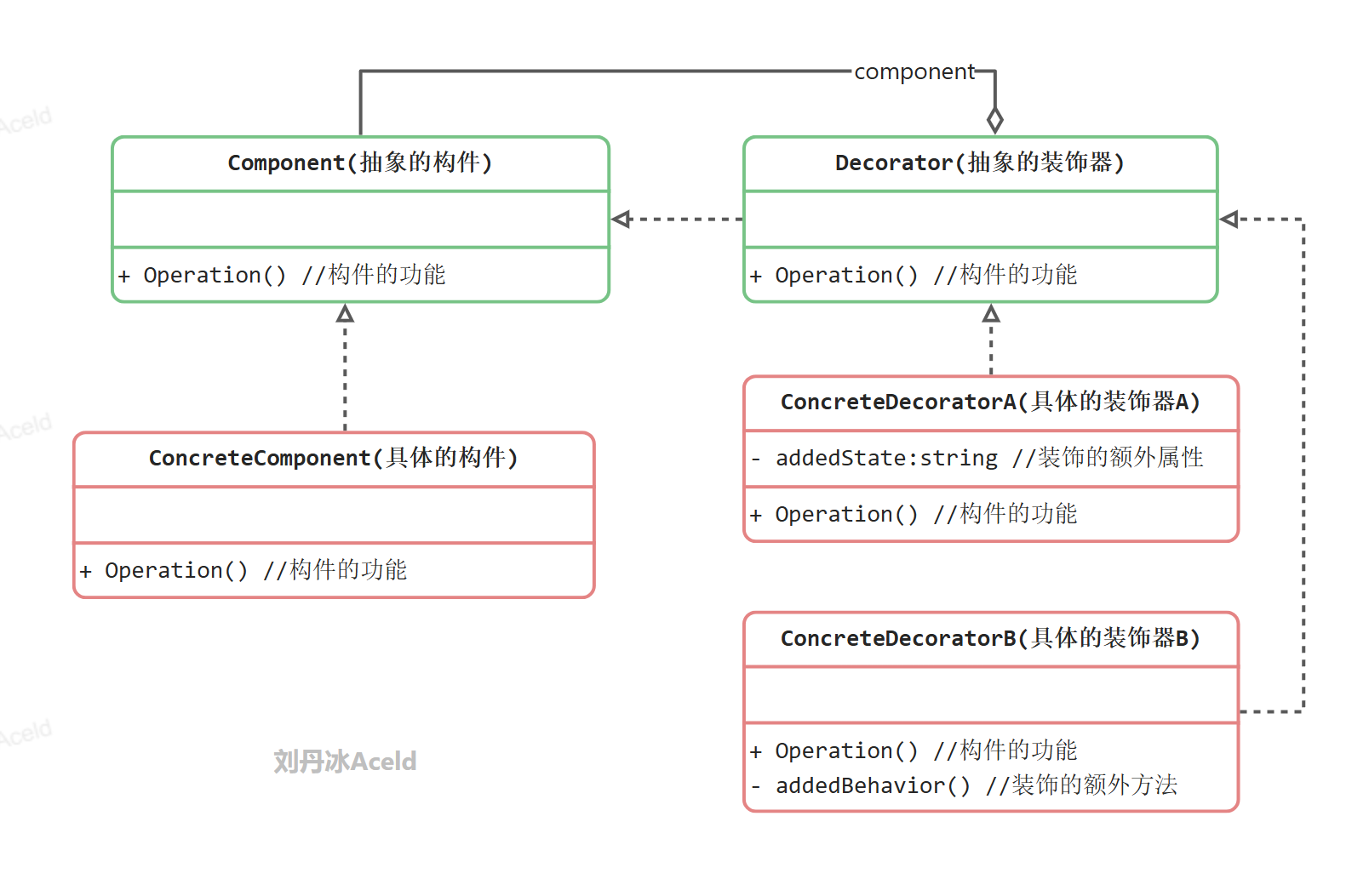
装饰模式中的代码实现
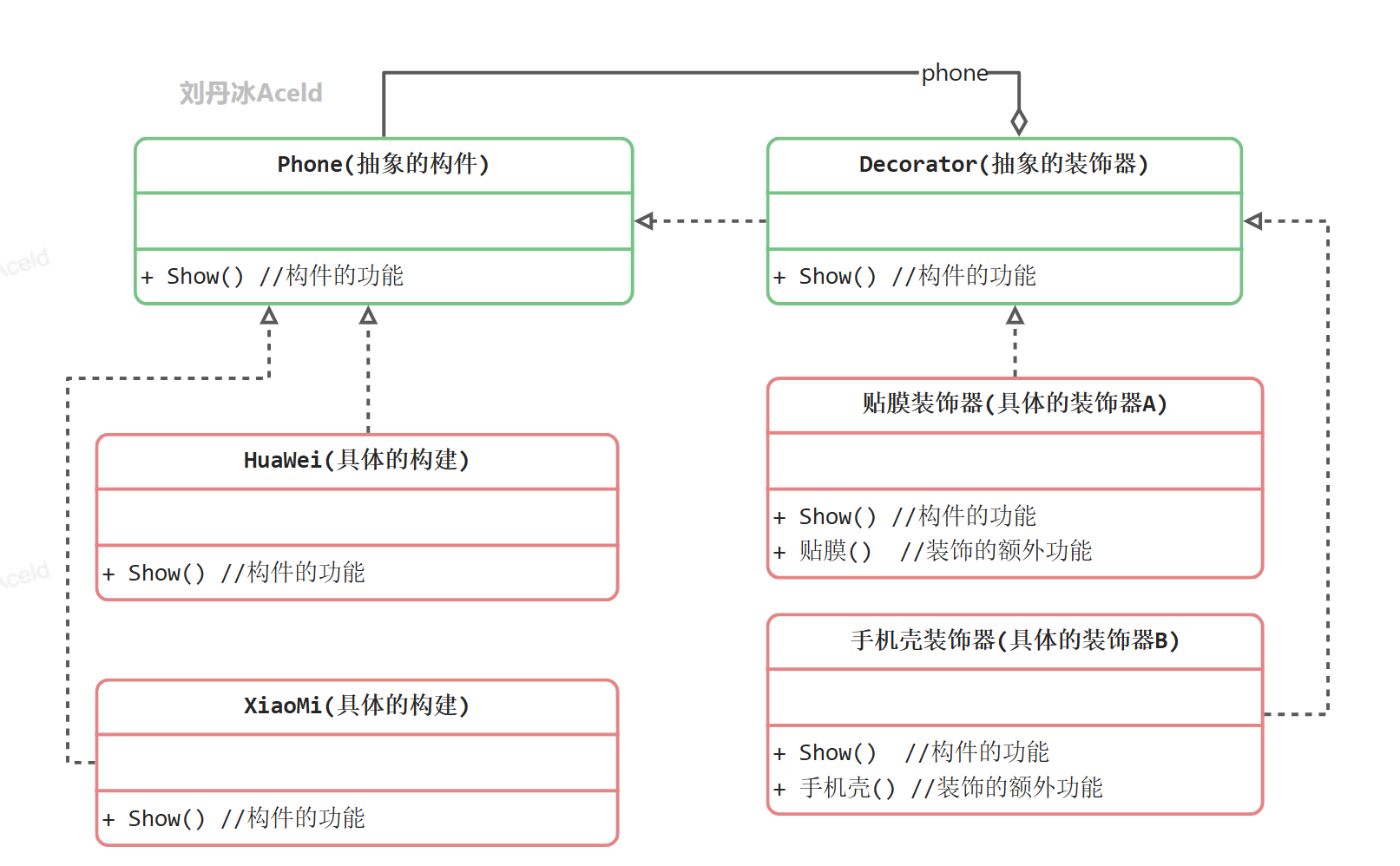
package decorator
import "fmt"
type Phone interface {
Show()
}
type HuaweiPhone struct{}
func (h HuaweiPhone) Show() {
fmt.Println("This is a Huawei phone")
}
type XiaomiPhone struct{}
func (xh XiaomiPhone) Show() {
fmt.Println("This is a Xiaomi phone")
}
type Decorator interface {
Show()
}
type AddScreenProtectionDecorator struct {
Phone
}
func (a AddScreenProtectionDecorator) Show() {
fmt.Println("Add screen protection")
a.Phone.Show()
}
type AddShellProtectionDecorator struct {
Phone
}
func (a AddShellProtectionDecorator) Show() {
fmt.Println("Add shell protection")
a.Phone.Show()
}
func DecorateTest() {
huaweiWithScreenProtection := AddScreenProtectionDecorator{HuaweiPhone{}}
huaweiWithScreenProtection.Show()
xiaomiWithShellProtection := AddShellProtectionDecorator{XiaomiPhone{}}
xiaomiWithShellProtection.Show()
}
装饰模式:
优点:
(1) 对于扩展一个对象的功能,装饰模式比继承更加灵活性,不会导致类的个数急剧增加。
(2) 可以通过一种动态的方式来扩展一个对象的功能,从而实现不同的行为。
(3) 可以对一个对象进行多次装饰。
(4) 具体构件类与具体装饰类可以独立变化,用户可以根据需要增加新的具体构件类和具体装饰类,原有类库代码无须改变,符合“开闭原则”。
缺点:
(1) 使用装饰模式进行系统设计时将产生很多小对象,大量小对象的产生势必会占用更多的系统资源,影响程序的性能。
(2) 装饰模式提供了一种比继承更加灵活机动的解决方案,但同时也意味着比继承更加易于出错,排错也很困难,对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为繁琐。
装饰模式(Decorator Pattern)和代理模式(Proxy Pattern)都是结构型设计模式,但它们的目的和应用场景有所不同。下面是对这两种模式的简要说明以及它们之间的区别:
装饰模式
-
目的:动态地给一个对象添加一些额外的职责。装饰模式提供了一种比继承更具弹性的替代方案。
-
适用场景:
- 当需要扩展一个类的功能或给一个类添加附加职责时。
- 当不能采用生成子类的方法进行扩展时,一种情况是可能有大量独立的扩展,为每一种组合将产生大量的子类,使得子类数目呈爆炸性增长。
-
结构:
- 包含一个抽象组件(Component)接口。
- 具体组件(Concrete Component)实现抽象组件接口。
- 抽象装饰器(Decorator)作为抽象组件的子类,持有具体组件的引用。
- 具体装饰器(Concrete Decorators)实现抽象装饰器,并添加职责。
-
特点:
- 动态性:可以在运行时动态地增加功能,也可以移除已有的功能。
- 透明性:客户端不需要知道具体的装饰器,只需与抽象组件交互即可。
- 复用性:可以创建多个装饰器,每个装饰器可以单独使用,也可以组合使用。
代理模式
-
目的:为另一个对象提供一个代理以控制对这个对象的访问。代理对象可以拦截客户端对真实对象的访问,做一些额外的处理。
-
适用场景:
- 远程代理(Remote Proxy):为远程对象提供本地代理。
- 虚拟代理(Virtual Proxy):当对象创建开销很大时,先创建一个代理对象,等到真正需要的时候再创建真实对象。
- 保护代理(Protection Proxy):控制对真实对象的访问权限。
-
结构:
- 包含一个主题(Subject)接口。
- 具体主题(Real Subject)实现主题接口。
- 代理(Proxy)也实现主题接口,并持有具体主题的引用。
-
特点:
- 透明性:客户端可以像对待真实对象一样对待代理对象。
- 控制访问:代理可以控制对真实对象的访问,比如缓存、权限验证等。
- 间接性:代理模式允许在客户端和真实对象之间建立间接关系。
不同之处
- 目的:装饰模式用于动态地给对象添加职责;代理模式用于控制对对象的访问。
- 使用场景:装饰模式适用于扩展对象的功能;代理模式适用于控制或优化对象的访问。
- 实现方式:装饰模式通过装饰器类来扩展功能;代理模式通过代理类来控制访问。
- 结构差异:装饰模式中的装饰器持有具体组件的实例;代理模式中的代理持有具体主题的实例。
总结来说,装饰模式关注的是对象的扩展,而代理模式关注的是对象的访问控制。在实际应用中,可以根据需要选择合适的模式来解决问题。
2.2.3 适配器模式
将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
适配器模式中的角色和职责
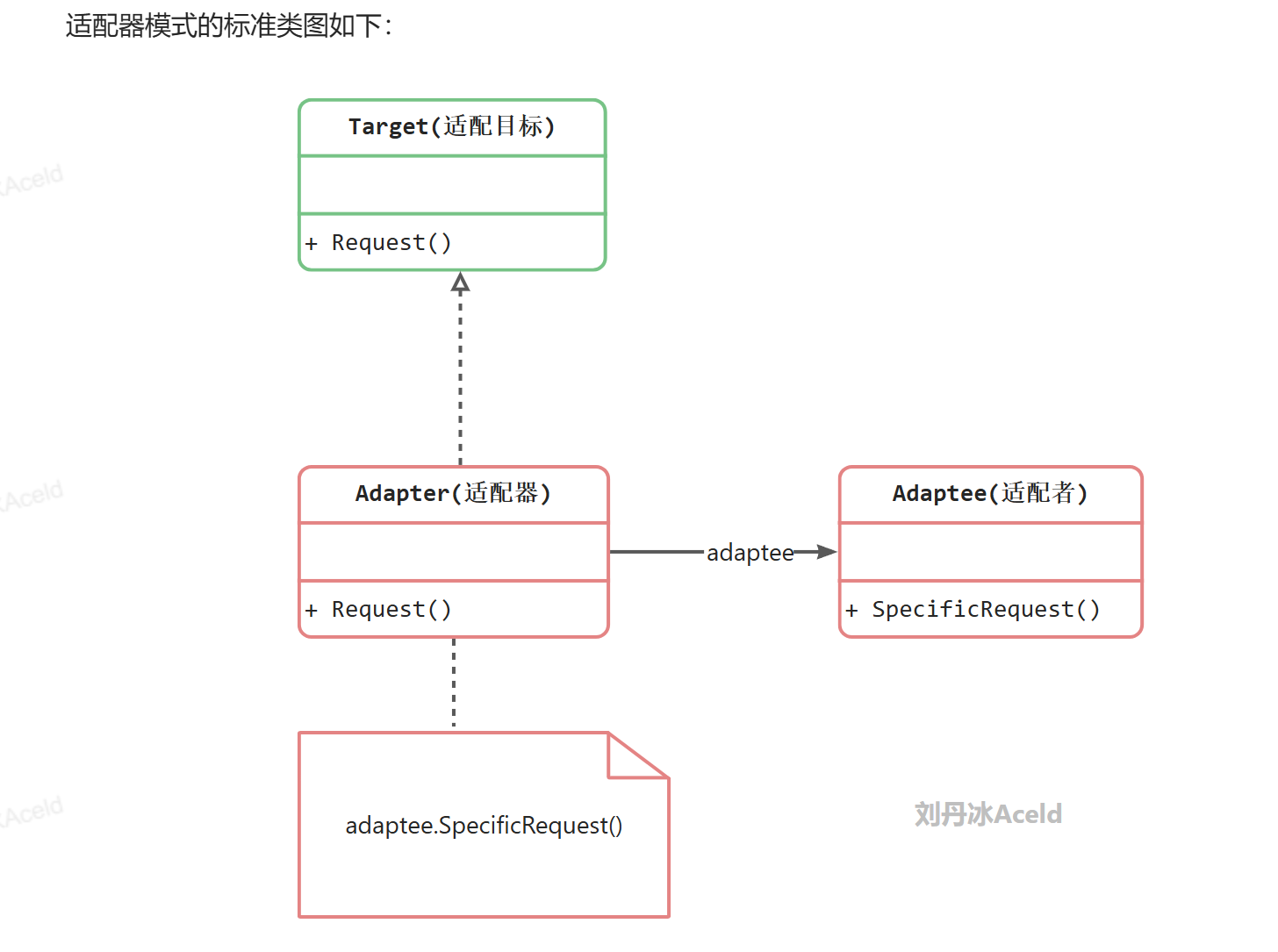
Target(目标抽象类):目标抽象类定义客户所需接口,可以是一个抽象类或接口,也可以是具体类。
Adapter(适配器类):适配器可以调用另一个接口,作为一个转换器,对Adaptee和Target进行适配,适配器类是适配器模式的核心,在对象适配器中,它通过继承Target并关联一个Adaptee对象使二者产生联系。
Adaptee(适配者类):适配者即被适配的角色,它定义了一个已经存在的接口,这个接口需要适配,适配者类一般是一个具体类,包含了客户希望使用的业务方法,在某些情况下可能没有适配者类的源代码。
根据对象适配器模式结构图,在对象适配器中,客户端需要调用request()方法,而适配者类Adaptee没有该方法,但是它所提供的specificRequest()方法却是客户端所需要的。为了使客户端能够使用适配者类,需要提供一个包装类Adapter,即适配器类。这个包装类包装了一个适配者的实例,从而将客户端与适配者衔接起来,在适配器的request()方法中调用适配者的specificRequest()方法。因为适配器类与适配者类是关联关系(也可称之为委派关系),所以这种适配器模式称为对象适配器模式。
代码实现
当然可以!让我们通过另一个例子来更好地理解适配器模式。这次我们将创建一个更简单的例子,涉及到一个天气预报系统,该系统需要与两种不同的温度传感器接口进行交互:一种是老式的摄氏温度传感器(CelsiusSensor),另一种是新式的华氏温度传感器(FahrenheitSensor)。
我们的目标是创建一个适配器,使我们可以使用相同的接口从这两种不同的传感器获取温度读数。
示例代码
package main
import (
"fmt"
)
// 定义老式摄氏温度传感器接口
type CelsiusSensor interface {
GetCelsiusTemperature() float64
}
// 定义新式华氏温度传感器接口
type FahrenheitSensor interface {
GetFahrenheitTemperature() float64
}
// 实现老式摄氏温度传感器
type OldCelsiusSensor struct{}
func (ocs *OldCelsiusSensor) GetCelsiusTemperature() float64 {
return 25.0 // 假设这是从老式传感器获得的温度
}
// 实现新式华氏温度传感器
type NewFahrenheitSensor struct{}
func (nfs *NewFahrenheitSensor) GetFahrenheitTemperature() float64 {
return 77.0 // 假设这是从新式传感器获得的温度
}
// 定义温度传感器适配器接口
type TemperatureSensor interface {
GetTemperature() float64
}
// 实现温度传感器适配器
type TemperatureSensorAdapter struct {
celsiusSensor CelsiusSensor
fahrenheitSensor FahrenheitSensor
}
func (tsa *TemperatureSensorAdapter) GetTemperature() float64 {
if tsa.celsiusSensor != nil {
return tsa.celsiusSensor.GetCelsiusTemperature()
} else if tsa.fahrenheitSensor != nil {
return (tsa.fahrenheitSensor.GetFahrenheitTemperature() - 32) * 5 / 9
}
return 0.0
}
func main() {
// 创建老式摄氏温度传感器实例
oldCelsiusSensor := &OldCelsiusSensor{}
// 创建新式华氏温度传感器实例
newFahrenheitSensor := &NewFahrenheitSensor{}
// 创建适配器
adapterForCelsius := &TemperatureSensorAdapter{celsiusSensor: oldCelsiusSensor}
adapterForFahrenheit := &TemperatureSensorAdapter{fahrenheitSensor: newFahrenheitSensor}
// 获取温度
fmt.Println("Temperature from old Celsius sensor:", adapterForCelsius.GetTemperature(), "°C")
fmt.Println("Temperature from new Fahrenheit sensor:", adapterForFahrenheit.GetTemperature(), "°C")
}
解释
- CelsiusSensor 接口定义了一个方法
GetCelsiusTemperature(),用于获取摄氏温度。 - FahrenheitSensor 接口定义了一个方法
GetFahrenheitTemperature(),用于获取华氏温度。 - OldCelsiusSensor 类实现了
CelsiusSensor 接口,返回一个固定的摄氏温度值。 - NewFahrenheitSensor 类实现了
FahrenheitSensor 接口,返回一个固定的华氏温度值。 - TemperatureSensor 接口定义了一个方法
GetTemperature(),用于获取温度,无论是摄氏还是华氏。 - TemperatureSensorAdapter 类实现了
TemperatureSensor 接口,并持有CelsiusSensor 或FahrenheitSensor 的引用。如果存在摄氏温度传感器,则直接返回摄氏温度;如果存在华氏温度传感器,则将其转换为摄氏温度并返回。
在 main 函数中,我们创建了两个传感器的实例以及相应的适配器,并调用了 GetTemperature() 方法来获取温度。
这个例子应该更容易理解一些,因为它涉及的是更常见的温度单位转换问题。
优缺点
优点:
(1) 将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无须修改原有结构。
(2) 增加了类的透明性和复用性,将具体的业务实现过程封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一个适配者类可以在多个不同的系统中复用。
(3) 灵活性和扩展性都非常好,可以很方便地更换适配器,也可以在不修改原有代码的基础上增加新的适配器类,完全符合“开闭原则”。
缺点:
适配器中置换适配者类的某些方法比较麻烦。
2.2.4 外观模式
根据迪米特法则,如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。
Facade模式也叫外观模式,是由GoF提出的23种设计模式中的一种。Facade模式为一组具有类似功能的类群,比如类库,子系统等等,提供一个一致的简单的界面。这个一致的简单的界面被称作facade。
外观模式中角色和职责
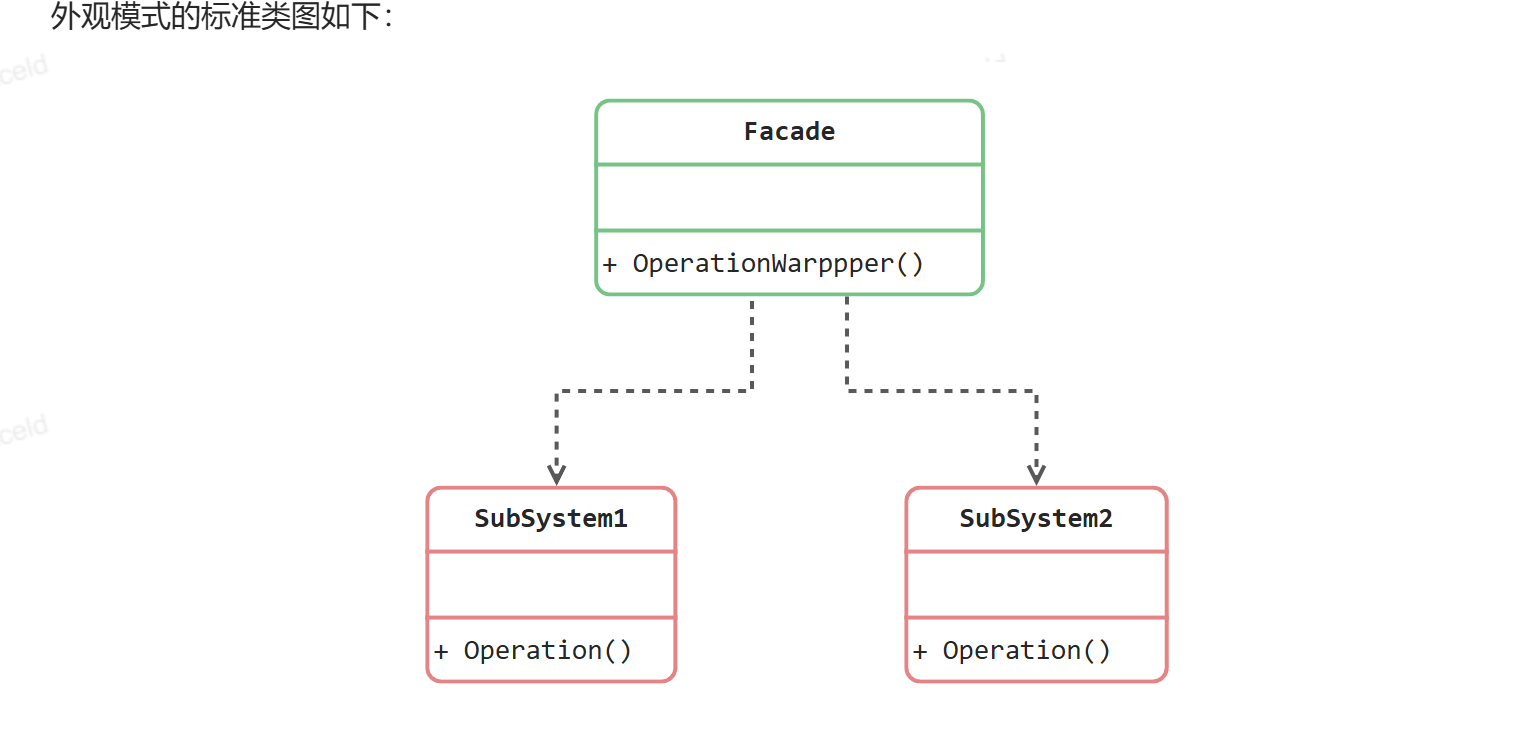
Façade(外观角色):为调用方, 定义简单的调用接口。
SubSystem(子系统角色):功能提供者。指提供功能的类群(模块或子系统)。
外观模式的案例
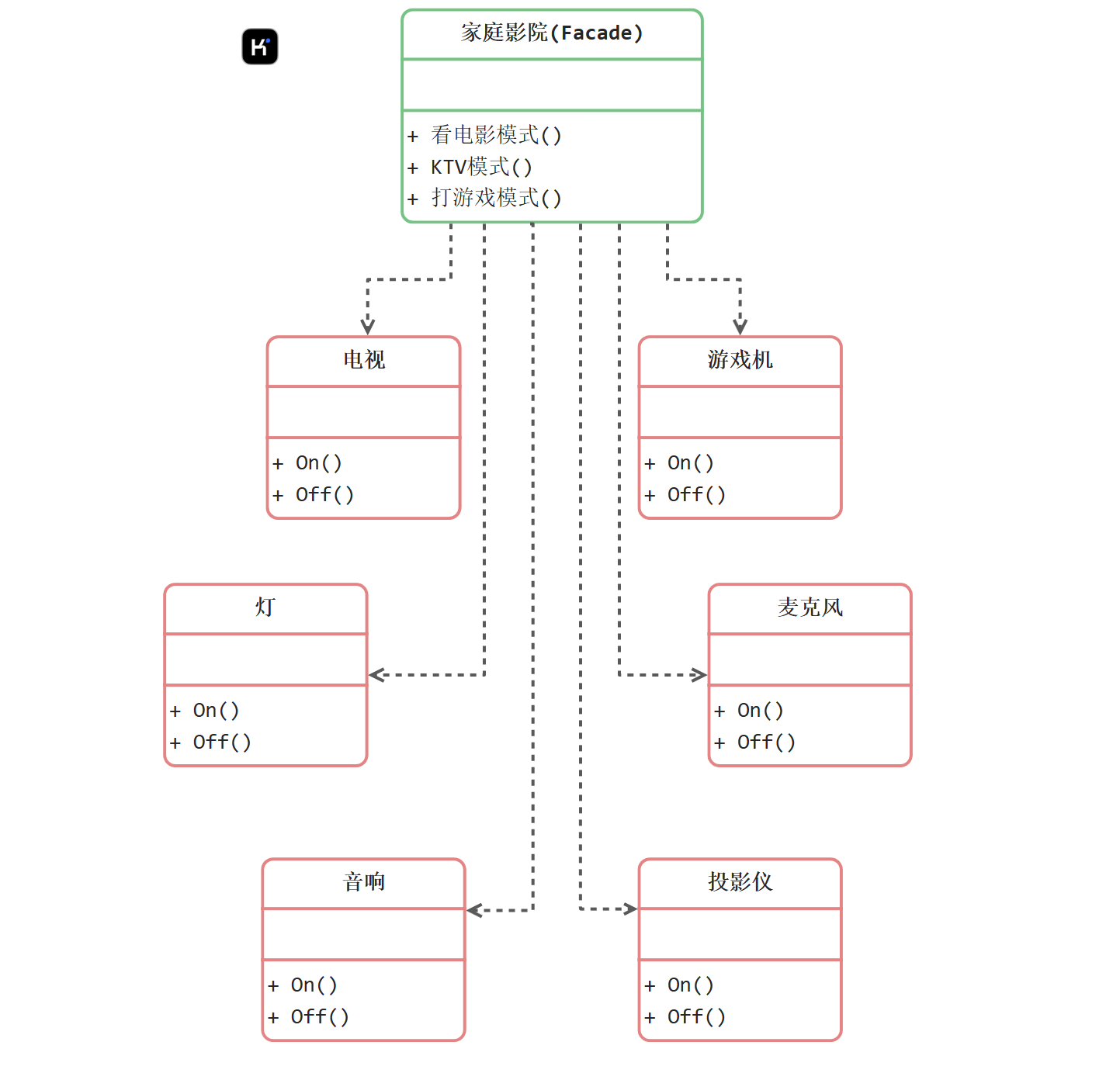
package appearance
import "fmt"
// 家庭影院(外观)
type HomePlayerFacade struct {
tv TV //电视
mp MicroPhone //麦克风
light Light //灯光
speaker Speaker //扬声器
xbox GameConsole //游戏机
pro Projector //投影仪
}
type Switch interface {
On()
Off()
}
type TV struct{}
type GameConsole struct{}
type Light struct{}
type MicroPhone struct{}
type Speaker struct{}
type Projector struct{}
func (t *TV) On() {
fmt.Println("TV is on")
}
func (t *TV) Off() {
fmt.Println("TV is off")
}
func (g *GameConsole) On() {
fmt.Println("GameConsole is on")
}
func (g *GameConsole) Off() {
fmt.Println("GameConsole is off")
}
func (l *Light) On() {
fmt.Println("Light is on")
}
func (l *Light) Off() {
fmt.Println("Light is off")
}
func (m *MicroPhone) On() {
fmt.Println("MicroPhone is on")
}
func (m *MicroPhone) Off() {
fmt.Println("MicroPhone is off")
}
func (s *Speaker) On() {
fmt.Println("Speaker is on")
}
func (s *Speaker) Off() {
fmt.Println("Speaker is off")
}
func (p *Projector) On() {
fmt.Println("Projector is on")
}
func (p *Projector) Off() {
fmt.Println("Projector is off")
}
// KTV MODE
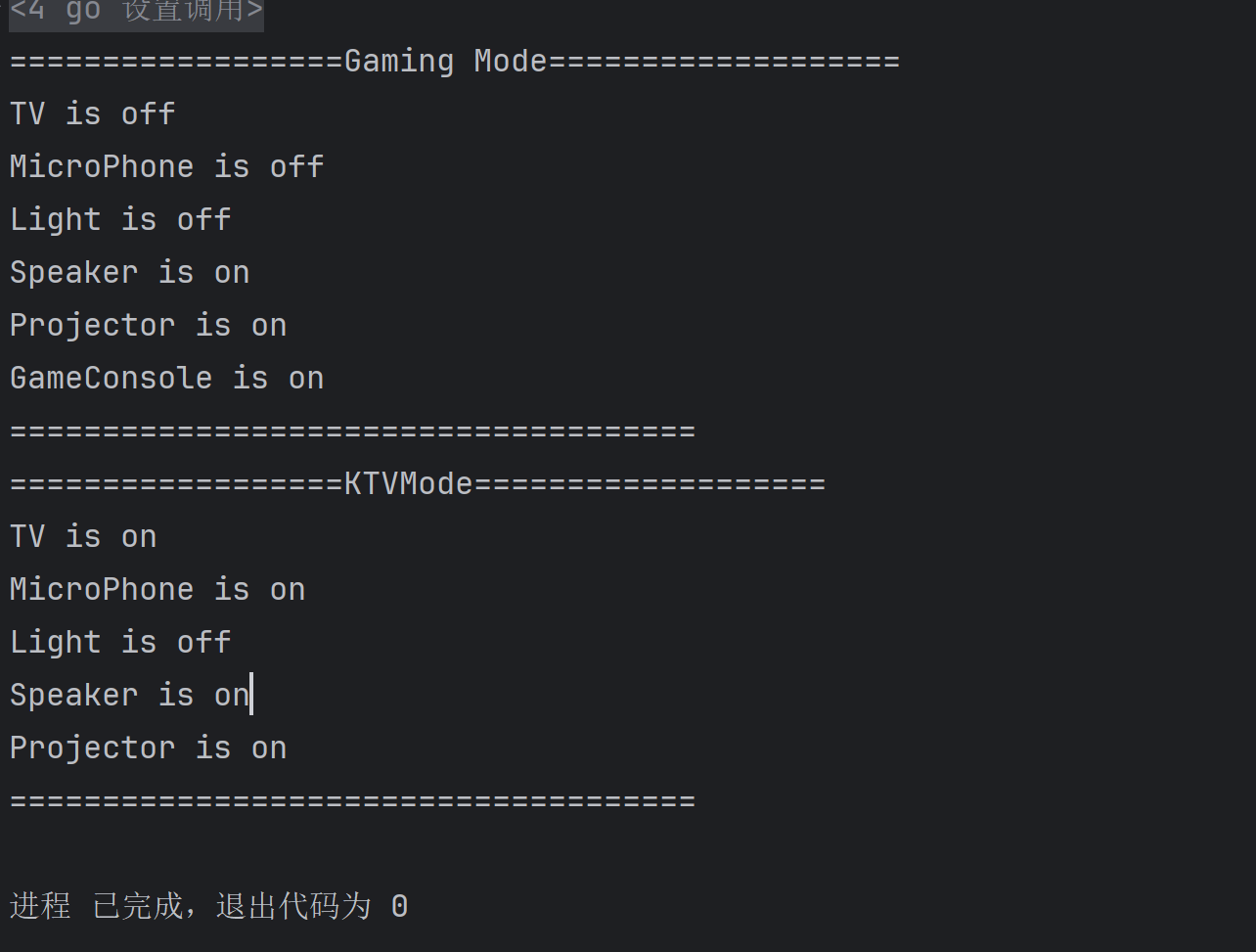
func (homePlayer *HomePlayerFacade) KTVMode() {
fmt.Println("==================KTVMode===================")
homePlayer.tv.On()
homePlayer.mp.On()
homePlayer.light.Off()
homePlayer.speaker.On()
homePlayer.pro.On()
fmt.Println("=====================================")
}
// Gaming MODE
func (homePlayer *HomePlayerFacade) GamingMode() {
fmt.Println("==================Gaming Mode===================")
homePlayer.tv.Off()
homePlayer.mp.Off()
homePlayer.light.Off()
homePlayer.speaker.On()
homePlayer.pro.On()
homePlayer.xbox.On()
fmt.Println("=====================================")
}
func AppearanceTest() {
homePlayer := HomePlayerFacade{}
homePlayer.GamingMode()
homePlayer.KTVMode()
}