
布隆过滤器
基本概念
布隆过滤器是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
实现原理
布隆过滤器使用一个位数组合多个哈希函数来实现。
位数组: 一个包含m位的数组,初始状态所有位都是0
哈希函数: k个不同的哈希函数,每个哈希函数都可以将集合中的元素映射到位数组中的一个位置。
插入元素
当要将一个元素添加到布隆过滤器的时候,使用k个哈希函数分别计算该元素的哈希值,然后将位数组中对应的k个位置都设置为1.
查询元素
当要查询一个元素是否存在于这个布隆过滤器中的时候,同样使用k个哈希函数计算该元素的哈希值,然后检查对应的k个位置是否都是1.
- 如果所有k个位置都是1,那么这个元素可能存在于集合中。
- 如果有任何一个位置是0,那么这个元素一定不存在于集合中
为什么不能检测“一定存在”?
检测元素时可以返回 “一定不存在” 和 “可能存在”,因为可能有多个元素映射到相同的 bit 上面,导致该位置为 1, 那么一个不存在的元素也可能会被误判为存在, 所以无法提供 “一定存在” 的语义保证。
为什么元素不允许被 “删除” ?
如果删除了某个元素,导致对应的 bit 位置为 0, 但是可能有多个元素映射到相同的 bit 上面,那么一个存在的元素会被误判为不存在 (这是不可接收的), 所以为了 “一定不存在” 的语义保证,元素不允许被删除。
优点
- 空间效率高: 布隆过滤器只需要存储一个位数组,而不需要存储实际的数据,因此空间效率很高。
- 时间效率高: 布隆过滤器使用哈希函数计算元素的哈希值,然后将对应的位置设置为1,因此时间效率很高。
- 可以处理大规模数据: 布隆过滤器可以处理大规模数据,因为它只需要存储一个位数组,而不需要存储实际的数据。
缺点
- 存在误判率: 布隆过滤器存在误判率,即可能会将一个不存在的元素误判为存在。
- 不支持删除操作: 布隆过滤器不支持删除操作,因为删除操作可能会导致误判率增加。
核心特征

应用场景
- 缓存穿透: 当一个请求查询一个不存在的缓存时,会导致请求直接访问数据库,此时可以使用布隆过滤器来判断该请求是否查询过,如果查询过则直接返回缓存中的数据,否则将请求发送到数据库中。
- 垃圾邮件过滤: 可以使用布隆过滤器来判断一个邮件是否是垃圾邮件,如果是垃圾邮件则直接过滤掉,否则将邮件发送到收件箱中。
- 业务记录计数器
- Web拦截: 可以使用布隆过滤器来判断一个请求是否已经被处理过,如果已经被处理过则直接返回缓存中的数据,否则将请求发送到后端服务中。
- URL去重: 可以使用布隆过滤器来判断一个URL是否已经被访问过,如果已经被访问过则直接返回缓存中的数据,否则将URL发送到后端服务中。
如何设计好一个布隆过滤器?

研究布隆过滤器源码
因为github上已经有golang实现的布隆过滤器了,我就不重复造轮子了。
仓库:github.com/bits-and-blooms/bloom
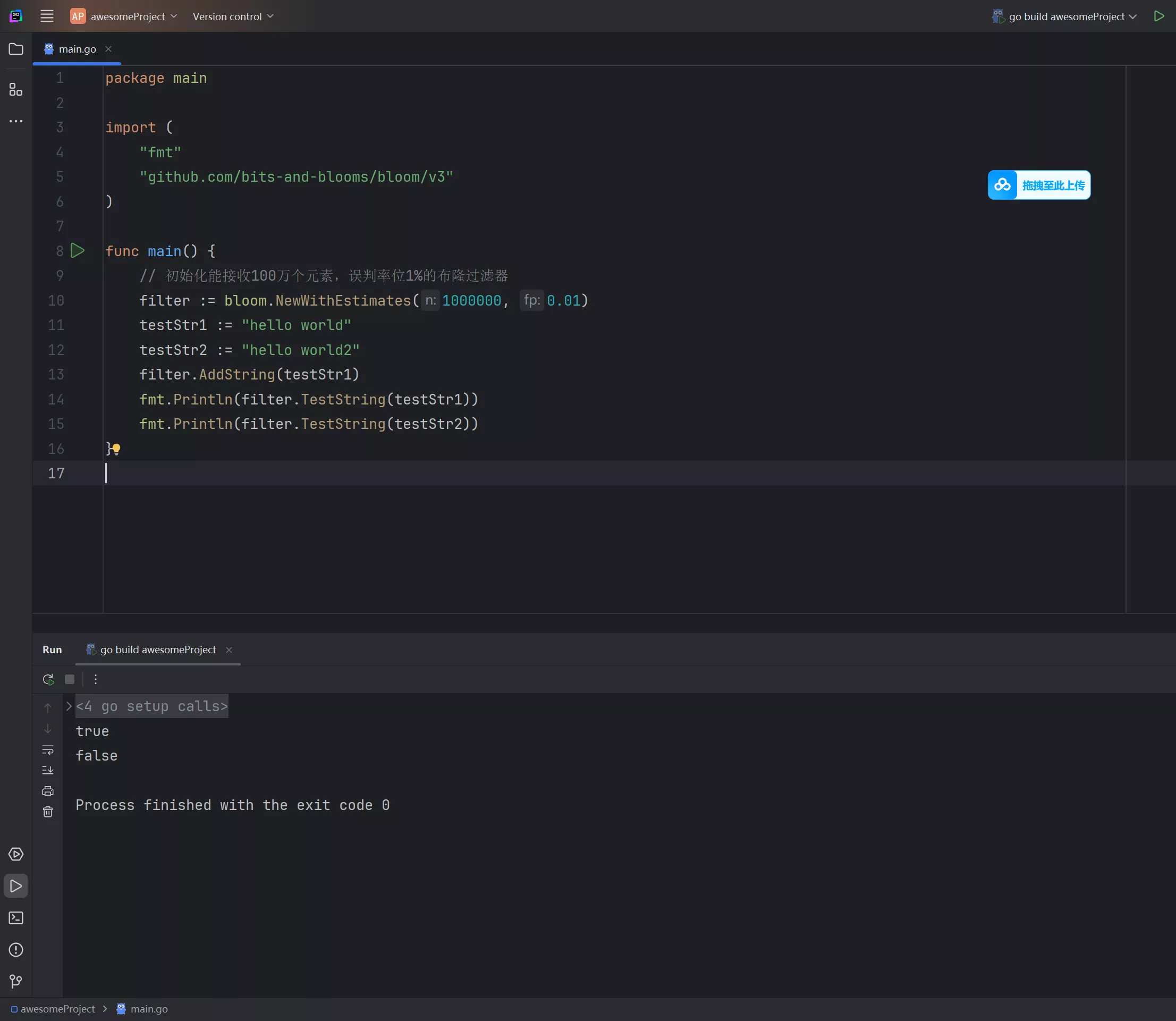
初始化过滤器时,应该尽可能明确需要的元素数量,因为 布隆过滤器 不是动态数据结构,如果指定的元素数量太少,则可能会超出误判概率范围。
使用
go get -u github.com/bits-and-blooms/bloom/v3
源码分析
BloomFilter 结构体表示一个 布隆过滤器,包含 3 个字段,分别对应上文提到的 布隆过滤器 的必要参数。
BoomFilter结构体
type BloomFilter struct {
m uint // 哈希空间大小,位数
k uint // 哈希函数数量
b *bitset.BitSet // bitmap
}

初始化BoomFilter
注释中的假阳性率
fp就是误判率
// New 创建一个新的 Bloom 过滤器,具有 _m_ 位和 _k_ 个哈希函数。
// 我们强制 _m_ 和 _k_ 至少为 1,以避免 panic。
func New(m uint, k uint) *BloomFilter {
return &BloomFilter{max(1, m), max(1, k), bitset.New(m)}
}
// NewWithEstimates 创建一个新的 Bloom 过滤器,用于大约 n 个元素,具有 fp 假阳性率。
func NewWithEstimates(n uint, fp float64) *BloomFilter {
m, k := EstimateParameters(n, fp)
return New(m, k)
}
// EstimateParameters 估计 m 和 k 的要求。
// 基于 https://bitbucket.org/ww/bloom/src/829aa19d01d9/bloom.go
// 经许可使用。
// EstimateParameters(n uint, p float64) 函数的作用是 基于预期的元素数量和目标假阳性率,估计 Bloom 过滤器所需的最佳参数 m(位数)和 k(哈希函数数量)。
func EstimateParameters(n uint, p float64) (m uint, k uint) {
m = uint(math.Ceil(-1 * float64(n) * math.Log(p) / math.Pow(math.Log(2), 2)))
k = uint(math.Ceil(math.Log(2) * float64(m) / float64(n)))
return
}
添加元素
// Add 数据添加到 Bloom 过滤器。返回过滤器(允许链式调用)
func (f *BloomFilter) Add(data []byte) *BloomFilter {
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
f.b.Set(f.location(h, i))
}
return f
}
// baseHashes 返回用于创建 k 个哈希的 data 的四个哈希值。
func baseHashes(data []byte) [4]uint64 {
var d digest128 // murmur hashing
hash1, hash2, hash3, hash4 := d.sum256(data)
return [4]uint64{
hash1, hash2, hash3, hash4,
}
}
// location 返回使用四个基本哈希值的第 i 个哈希位置
func (f *BloomFilter) location(h [4]uint64, i uint) uint {
return uint(location(h, i) % uint64(f.m))
}
// location 返回使用四个基本哈希值的第 i 个哈希位置
func location(h [4]uint64, i uint) uint64 {
ii := uint64(i)
return h[ii%2] + ii*h[2+(((ii+(ii%2))%4)/2)]
}
检测元素
BloomFilter.Test 方法检测一个元素是否存在于 布隆过滤器 中,可以看到,其内部实现就是 BloomFilter.Add 方法的逆过程。

// Test 如果数据在 BloomFilter 中则返回 true,否则返回 false。
// 如果为 true,则结果可能是假阳性。如果为 false,则数据
// 肯定不在集合中。
func (f *BloomFilter) Test(data []byte) bool {
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
if !f.b.Test(f.location(h, i)) {
return false
}
}
return true
}
源码
/*
Package bloom 提供用于创建 Bloom 过滤器的各种数据结构和方法。
Bloom 过滤器是对 _n_ 个项目集合的一种表示,其主要要求是进行成员资格查询;_即_,判断一个项目是否是集合的成员。
Bloom 过滤器有两个参数:_m_,最大大小(通常是表示集合的基数的合理倍数),和 _k_,对集合元素进行哈希函数的数量。(实际使用的哈希函数也很重要,但这不是此实现的参数)。Bloom 过滤器由 BitSet 支持;一个键通过设置每个哈希函数值(模 _m_)处的位来表示在过滤器中。集合成员资格通过_测试_每个哈希函数值(同样,模 _m_)处的位是否被设置来完成。如果是,该项目就在集合中。如果该项目实际上在集合中,Bloom 过滤器永远不会失败(真阳性率为 1.0);但它易受假阳性的影响。关键在于正确选择 _k_ 和 _m_。
m : 代表 Bloom 过滤器中 位的总数 (number of bits) 。可以将其理解为 Bloom 过滤器占用的空间大小。 更大的 m 可以降低假阳性率,但会消耗更多的内存。
k : 代表 哈希函数的数量 (number of hash functions) 。 每个添加到 Bloom 过滤器的元素都会被 k 个不同的哈希函数处理,并设置相应的位。 增加 k 可以降低假阳性率,直至达到一个最佳值,超过这个值后,由于更多的位被设置,假阳性率会开始上升
在此实现中,使用的哈希函数是 murmurhash,一种非加密哈希函数。
此实现接受 []byte 类型的键用于设置和测试。因此,要添加一个字符串项目 "Love":
uint n = 1000
filter := bloom.New(20*n, 5) // 加载量为 20,5 个键
filter.Add([]byte("Love"))
类似地,要测试 "Love" 是否在布隆过滤器中:
if filter.Test([]byte("Love"))
对于数值数据,我建议你查看 binary/encoding 库。但是,例如,要添加一个 uint32 到过滤器:
i := uint32(100)
n1 := make([]byte,4)
binary.BigEndian.PutUint32(n1,i)
f.Add(n1)
最后,有一种方法可以估计具有 _m_ 位和 _k_ 个哈希函数的 Bloom 过滤器对于大小为 _n_ 的集的假阳性率:
if bloom.EstimateFalsePositiveRate(20*n, 5, n) > 0.001 ...
你可以使用它来验证计算出的 m, k 参数:
m, k := bloom.EstimateParameters(n, fp)
ActualfpRate := bloom.EstimateFalsePositiveRate(m, k, n)
或者
f := bloom.NewWithEstimates(n, fp)
ActualfpRate := bloom.EstimateFalsePositiveRate(f.m, f.k, n)
你希望 ActualfpRate 在这些情况下接近所需的 fp。
EstimateFalsePositiveRate 函数创建一个临时的 Bloom 过滤器。它也相对昂贵,仅用于验证。
*/
package bloom
import (
"bytes"
"encoding/binary"
"encoding/json"
"fmt"
"io"
"math"
"github.com/bits-and-blooms/bitset"
)
// A BloomFilter 是对 _n_ 个项目集合的一种表示,其主要要求是进行成员资格查询;_即_,判断一个项目是否是集合的成员。
type BloomFilter struct {
m uint // 哈希空间大小,位数
k uint // 哈希函数数量
b *bitset.BitSet // bitmap
}
func max(x, y uint) uint {
if x > y {
return x
}
return y
}
// New 创建一个新的 Bloom 过滤器,具有 _m_ 位和 _k_ 个哈希函数。
// 我们强制 _m_ 和 _k_ 至少为 1,以避免 panic。
func New(m uint, k uint) *BloomFilter {
return &BloomFilter{max(1, m), max(1, k), bitset.New(m)}
}
// From 创建一个新的 Bloom 过滤器,具有 len(_data_) * 64 位和 _k_ 个哈希函数。
// 数据切片不会被重置。
func From(data []uint64, k uint) *BloomFilter {
m := uint(len(data) * 64)
return FromWithM(data, m, k)
}
// FromWithM 创建一个新的 Bloom 过滤器,具有 _m_ 长度,_k_ 个哈希函数。
// 数据切片不会被重置。
func FromWithM(data []uint64, m, k uint) *BloomFilter {
return &BloomFilter{m, k, bitset.From(data)}
}
// baseHashes 返回用于创建 k 个哈希的 data 的四个哈希值。
func baseHashes(data []byte) [4]uint64 {
var d digest128 // murmur hashing
hash1, hash2, hash3, hash4 := d.sum256(data)
return [4]uint64{
hash1, hash2, hash3, hash4,
}
}
// location 返回使用四个基本哈希值的第 i 个哈希位置
func location(h [4]uint64, i uint) uint64 {
ii := uint64(i)
return h[ii%2] + ii*h[2+(((ii+(ii%2))%4)/2)]
}
// location 返回使用四个基本哈希值的第 i 个哈希位置
func (f *BloomFilter) location(h [4]uint64, i uint) uint {
return uint(location(h, i) % uint64(f.m))
}
// EstimateParameters 估计 m 和 k 的要求。
// 基于 https://bitbucket.org/ww/bloom/src/829aa19d01d9/bloom.go
// 经许可使用。
func EstimateParameters(n uint, p float64) (m uint, k uint) {
m = uint(math.Ceil(-1 * float64(n) * math.Log(p) / math.Pow(math.Log(2), 2)))
k = uint(math.Ceil(math.Log(2) * float64(m) / float64(n)))
return
}
// NewWithEstimates 创建一个新的 Bloom 过滤器,用于大约 n 个项目,具有 fp 假阳性率。
func NewWithEstimates(n uint, fp float64) *BloomFilter {
m, k := EstimateParameters(n, fp)
return New(m, k)
}
// Cap 返回 Bloom 过滤器的容量,_m_。
func (f *BloomFilter) Cap() uint {
return f.m
}
// K 返回 BloomFilter 中使用的哈希函数的数量。
func (f *BloomFilter) K() uint {
return f.k
}
// BitSet 返回此过滤器的底层 bitset。
func (f *BloomFilter) BitSet() *bitset.BitSet {
return f.b
}
// Add 数据添加到 Bloom 过滤器。返回过滤器(允许链式调用)
func (f *BloomFilter) Add(data []byte) *BloomFilter {
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
f.b.Set(f.location(h, i))
}
return f
}
// Merge 合并来自两个 Bloom 过滤器的数据。
func (f *BloomFilter) Merge(g *BloomFilter) error {
// 确保 m 和 k 相同,否则合并没有实际用途。
if f.m != g.m {
return fmt.Errorf("m 不匹配: %d != %d", f.m, g.m)
}
if f.k != g.k {
return fmt.Errorf("k 不匹配: %d != %d", f.m, g.m)
}
f.b.InPlaceUnion(g.b)
return nil
}
// Copy 创建 Bloom 过滤器的副本。
func (f *BloomFilter) Copy() *BloomFilter {
fc := New(f.m, f.k)
fc.Merge(f) // #nosec
return fc
}
// AddString 将字符串添加到 Bloom 过滤器。返回过滤器(允许链式调用)
func (f *BloomFilter) AddString(data string) *BloomFilter {
return f.Add([]byte(data))
}
// Test 如果数据在 BloomFilter 中则返回 true,否则返回 false。
// 如果为 true,则结果可能是假阳性。如果为 false,则数据
// 肯定不在集合中。
func (f *BloomFilter) Test(data []byte) bool {
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
if !f.b.Test(f.location(h, i)) {
return false
}
}
return true
}
// TestString 如果字符串在 BloomFilter 中则返回 true,否则返回 false。
// 如果为 true,则结果可能是假阳性。如果为 false,则数据
// 肯定不在集合中。
func (f *BloomFilter) TestString(data string) bool {
return f.Test([]byte(data))
}
// TestLocations 如果所有位置都在 BloomFilter 中设置,则返回 true,否则返回 false。
func (f *BloomFilter) TestLocations(locs []uint64) bool {
for i := 0; i < len(locs); i++ {
if !f.b.Test(uint(locs[i] % uint64(f.m))) {
return false
}
}
return true
}
// TestAndAdd 等同于调用 Test(data) 然后 Add(data)。
// 过滤器会被无条件地写入:即使元素已经存在,
// 相应的位仍然会被设置。参见 TestOrAdd。
// 返回 Test 的结果。
func (f *BloomFilter) TestAndAdd(data []byte) bool {
present := true
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
l := f.location(h, i)
if !f.b.Test(l) {
present = false
}
f.b.Set(l)
}
return present
}
// TestAndAddString 等同于调用 Test(string) 然后 Add(string)。
// 过滤器会被无条件地写入:即使字符串已经存在,
// 相应的位仍然会被设置。参见 TestOrAdd。
// 返回 Test 的结果。
func (f *BloomFilter) TestAndAddString(data string) bool {
return f.TestAndAdd([]byte(data))
}
// TestOrAdd 等同于调用 Test(data) 然后当不存在时 Add(data)。
// 如果元素已经在过滤器中,那么过滤器不会改变。
// 返回 Test 的结果。
func (f *BloomFilter) TestOrAdd(data []byte) bool {
present := true
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
l := f.location(h, i)
if !f.b.Test(l) {
present = false
f.b.Set(l)
}
}
return present
}
// TestOrAddString 等同于调用 Test(string) 然后当不存在时 Add(string)。
// 如果字符串已经在过滤器中,那么过滤器不会改变。
// 返回 Test 的结果。
func (f *BloomFilter) TestOrAddString(data string) bool {
return f.TestOrAdd([]byte(data))
}
// ClearAll 清除 Bloom 过滤器中的所有数据,移除所有键。
func (f *BloomFilter) ClearAll() *BloomFilter {
f.b.ClearAll()
return f
}
// EstimateFalsePositiveRate 返回,对于一个具有 m 位和 k 个哈希函数的 BloomFilter,
// 当存储 n 个条目时, 对假阳性率的估计。这是一个经验性的,相对比较慢的测试,
// 使用整数作为键。 此函数可用于验证实现。
func EstimateFalsePositiveRate(m, k, n uint) (fpRate float64) {
rounds := uint32(100000)
// 我们构造一个新的过滤器。
f := New(m, k)
n1 := make([]byte, 4)
// 我们用 n 个值填充过滤器。
for i := uint32(0); i < uint32(n); i++ {
binary.BigEndian.PutUint32(n1, i)
f.Add(n1)
}
fp := 0
// 测试 rounds 的数量。
for i := uint32(0); i < rounds; i++ {
binary.BigEndian.PutUint32(n1, i+uint32(n)+1)
if f.Test(n1) {
fp++
}
}
fpRate = float64(fp) / (float64(rounds))
return
}
// 逼近项目数量
// https://en.wikipedia.org/wiki/Bloom_filter#Approximating_the_number_of_items_in_a_Bloom_filter
func (f *BloomFilter) ApproximatedSize() uint32 {
x := float64(f.b.Count())
m := float64(f.Cap())
k := float64(f.K())
size := -1 * m / k * math.Log(1-x/m) / math.Log(math.E)
return uint32(math.Floor(size + 0.5)) // round
}
// bloomFilterJSON 是一个非导出的类型,用于marshal/unmarshal BloomFilter 结构体。
type bloomFilterJSON struct {
M uint `json:"m"`
K uint `json:"k"`
B *bitset.BitSet `json:"b"`
}
// MarshalJSON 实现了 json.Marshaler 接口.
func (f BloomFilter) MarshalJSON() ([]byte, error) {
return json.Marshal(bloomFilterJSON{f.m, f.k, f.b})
}
// UnmarshalJSON 实现了 json.Unmarshaler 接口。
func (f *BloomFilter) UnmarshalJSON(data []byte) error {
var j bloomFilterJSON
err := json.Unmarshal(data, &j)
if err != nil {
return err
}
f.m = j.M
f.k = j.K
f.b = j.B
return nil
}
// WriteTo 将 BloomFilter 的二进制表示写入 i/o 流。
// 它返回写入的字节数。
//
// 性能:如果此函数用于写入磁盘或网络连接,则将流包装在 bufio.Writer 中可能是有益的。
// 例如:
//
// f, err := os.Create("myfile")
// w := bufio.NewWriter(f)
func (f *BloomFilter) WriteTo(stream io.Writer) (int64, error) {
err := binary.Write(stream, binary.BigEndian, uint64(f.m))
if err != nil {
return 0, err
}
err = binary.Write(stream, binary.BigEndian, uint64(f.k))
if err != nil {
return 0, err
}
numBytes, err := f.b.WriteTo(stream)
return numBytes + int64(2*binary.Size(uint64(0))), err
}
// ReadFrom 从 i/o 流读取 BloomFilter 的二进制表示(例如,可能由 WriteTo() 写入的内容)。
// 它返回读取的字节数.
//
// 性能:如果此函数用于从磁盘或网络连接读取数据,则将流包装在 bufio.Reader 中可能是有益的。
// 例如:
//
// f, err := os.Open("myfile")
// r := bufio.NewReader(f)
func (f *BloomFilter) ReadFrom(stream io.Reader) (int64, error) {
var m, k uint64
err := binary.Read(stream, binary.BigEndian, &m)
if err != nil {
return 0, err
}
err = binary.Read(stream, binary.BigEndian, &k)
if err != nil {
return 0, err
}
b := &bitset.BitSet{}
numBytes, err := b.ReadFrom(stream)
if err != nil {
return 0, err
}
f.m = uint(m)
f.k = uint(k)
f.b = b
return numBytes + int64(2*binary.Size(uint64(0))), nil
}
// GobEncode 实现了 gob.GobEncoder 接口.
func (f *BloomFilter) GobEncode() ([]byte, error) {
var buf bytes.Buffer
_, err := f.WriteTo(&buf)
if err != nil {
return nil, err
}
return buf.Bytes(), nil
}
// GobDecode 实现了 gob.GobDecoder 接口。
func (f *BloomFilter) GobDecode(data []byte) error {
buf := bytes.NewBuffer(data)
_, err := f.ReadFrom(buf)
return err
}
// MarshalBinary 实现了 binary.BinaryMarshaler 接口.
func (f *BloomFilter) MarshalBinary() ([]byte, error) {
var buf bytes.Buffer
_, err := f.WriteTo(&buf)
if err != nil {
return nil, err
}
return buf.Bytes(), nil
}
// UnmarshalBinary 实现了 binary.BinaryUnmarshaler 接口。
func (f *BloomFilter) UnmarshalBinary(data []byte) error {
buf := bytes.NewBuffer(data)
_, err := f.ReadFrom(buf)
return err
}
// Equal 测试两个 Bloom 过滤器是否相等。
func (f *BloomFilter) Equal(g *BloomFilter) bool {
return f.m == g.m && f.k == g.k && f.b.Equal(g.b)
}
// Locations 返回表示数据项的哈希位置列表。
func Locations(data []byte, k uint) []uint64 {
locs := make([]uint64, k)
// 计算位置。
h := baseHashes(data)
for i := uint(0); i < k; i++ {
locs[i] = location(h, i)
}
return locs
}